
Generative Adversarial Nets (GAN) 1: GAN과 DCGAN 설명
이번 포스팅에서는 적대적 생성 네트워크 (Generative Adversarial Nets, GAN)을 정리해보고자 합니다.
Motivation
GAN이라는 모델 자체는 딥러닝을 처음 공부할 때 접해본 적 있지만, 아직까지 사용해 볼 일이 없어서 개념만 알고 넘어갔습니다. 그러다 최근 개인적으로 GAN을 활용할 사이드프로젝트를 할 일이 생겨 제대로 공부하기 위해 겸사겸사 정리합니다.
GAN
GAN은 2014년, Yoshua Bengio의 제자 Ian Goodfellow가 제안한 이미지 생성 모델입니다. 2014년 발표된 이후, 세간의 엄청난 관심을 끌며 많은 연구가 이루어져, 지금까지 다양한 GAN 모델이 개발되었습니다.
Basic idea
딥 러닝의 아버지라고도 불리우는 Yann Lecun 교수는 GAN을 가리켜 최근 10년 동안 머신러닝 분야에서 가장 혁신적인 아이디어라고 말했다고 합니다.
실제로 GAN의 기본 개념은 정말 간단하지만 참신합니다.
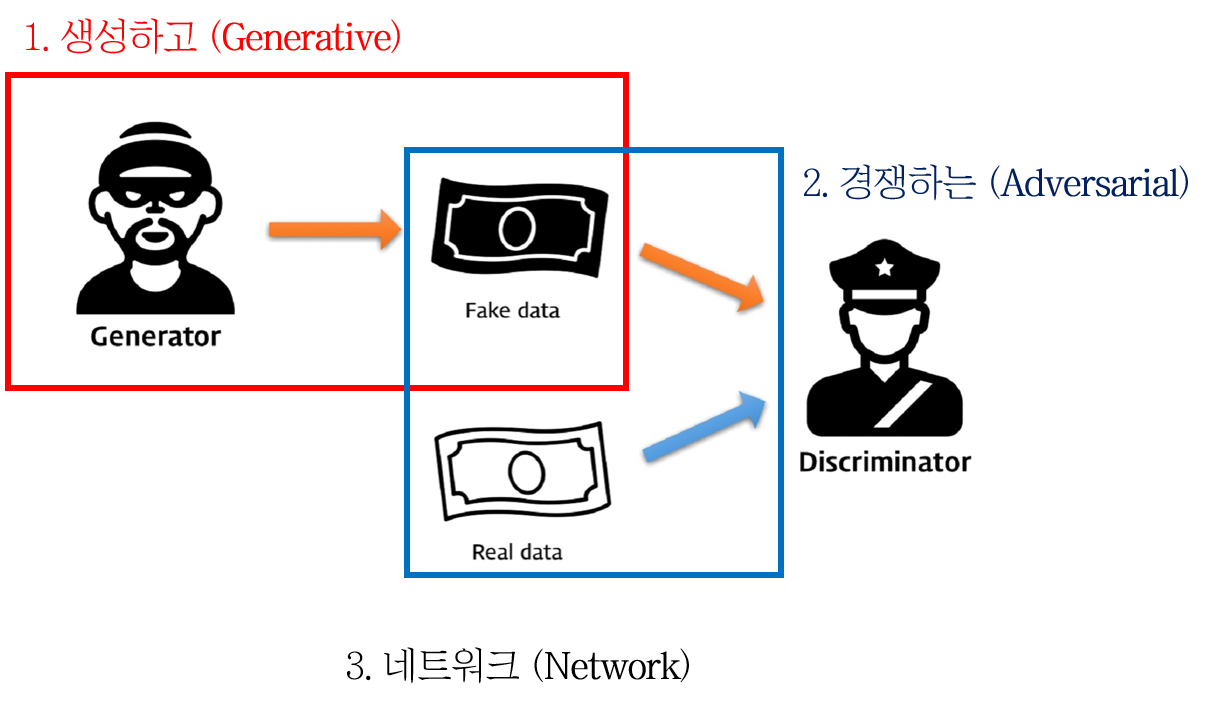
그 유명한 지폐 위조범과 경찰 이야기입니다.
- 지폐 위조범은 가능한 진짜같은 가짜 지폐를 만들어내야 합니다.
- 경찰은 지폐 위조범이 만든 가짜 지폐를 가짜로, 진짜 지폐는 진짜로 구별해야내야 합니다.
- 이 둘은 서로 계속해서 경쟁해나갑니다. 지폐 위조범은 점점 더 진짜 같은 가짜 지폐를 만들고, 경찰은 점점 더 구별 능력을 개선시킵니다.
- 어느 순간이 되면 지폐 위조범의 능력이 극에 달해 진짜와 다름없는 가짜 지폐를 만들게 됩니다. 이 때 경찰의 구별 확률은 \(\frac{1}{2}\)로 수렴합니다.
- 이 상태에서 만들어진 가짜 지폐는 진짜 지폐처럼 보일 것입니다.
즉, GAN이라는 것은 이름 그대로 세 단계로 구분됩니다.
- Generative: 가짜 이미지를 생성하는 Generative model \(G\)가 있습니다.
- Adversarial: \(G\)는 진짜와 가짜 이미지를 구별하는 Discriminative model \(D\)와 적대적으로 대립하며 각자 학습해나갑니다.
- Network: \(G\)와 \(D\)는 Neural network입니다.
GAN family
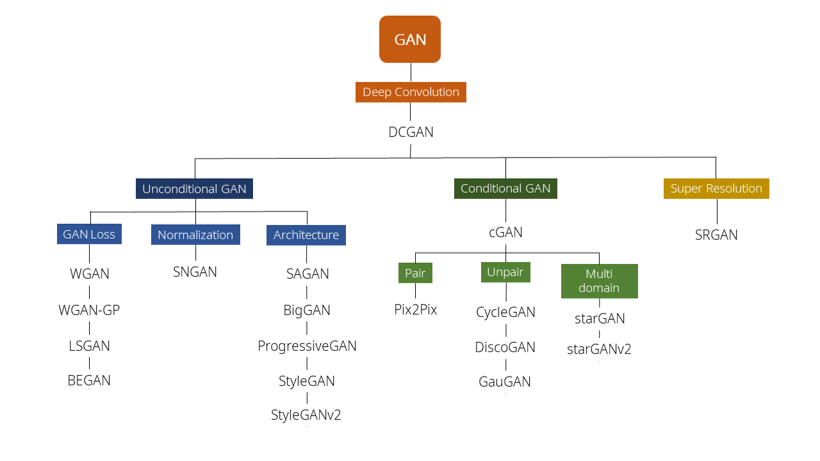
위 이미지는 다른 분이 GAN의 시작부터 최신 트렌드까지를 잘 정리해둔 글에서 가져왔습니다. 내용이 많이 요약되어서 전체적인 흐름만 참고하고, 자세한 내용은 따로 찾아봐야겠지만 좋은 글인 것 같습니다.
계보(?)를 보면, GAN이 맨 처음 제안된 후, DCGAN이라는 모델이 제안됩니다. 그리고 그 다음 모델들은 모두 DCGAN으로부터 나온 (?) 것을 볼 수 있습니다.
여기서 ‘DCGAN이라는 모델이 GAN 연구의 엄청난 한 획을 그었구나…‘라는 것을 알 수 있습니다.
따라서 오늘 포스팅에서는 GAN과 DCGAN을 함께 정리해보도록 하겠습니다.
GAN
Paper (2014)

GAN의 시작인 Generative Adversarial Nets라는 논문은 2014년, Ian Goodfellow에 의해 발표되었습니다.
Key concept
당연한 말이겠지만, 이 논문 자체는 위에서 살펴본 아이디어와 동일합니다.
그런데 latent space \(z\) 라는 개념이 등장합니다. 지폐 위조범이 지폐를 만들 때, 종이가 필요하겠죠. 이 종이는 그냥 임의의 종이를 이용할 겁니다.
실제 GAN의 구현에서도 종이의 역할을 하는 noise가 필요합니다. 즉, Generative model \(G\)가 하는 일 \(G(z)\)은 noise (\z\)로부터 가짜 이미지로 맵핑하는 것이라고 볼 수 있습니다.
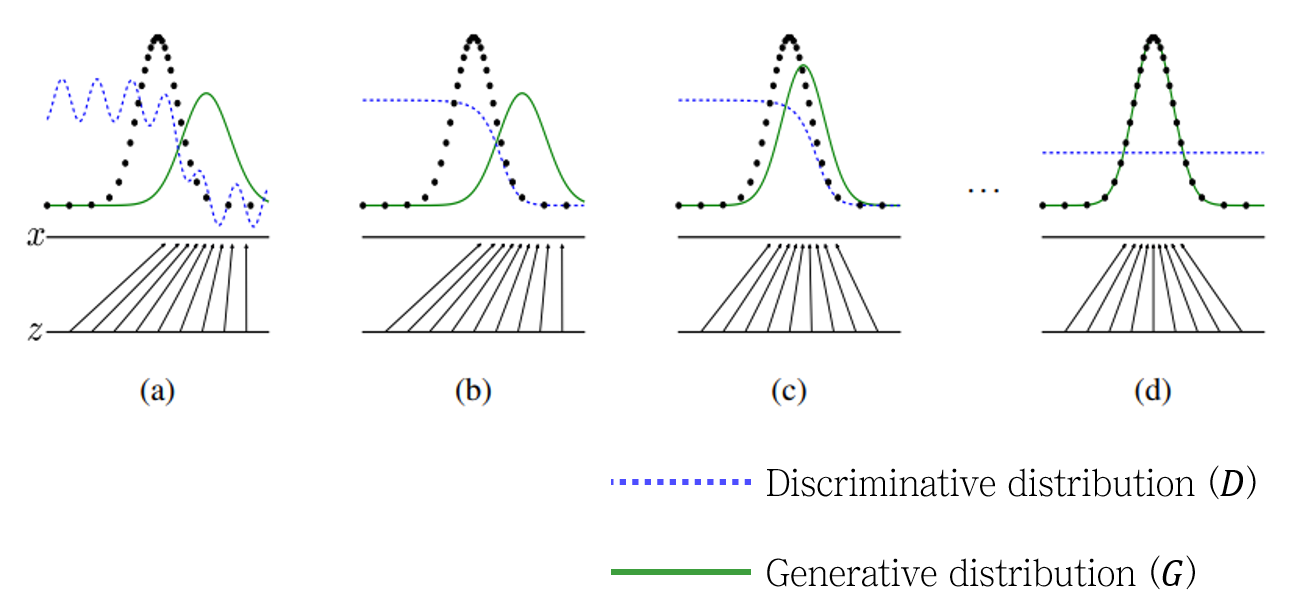
위 그림에서 (a)-(d) 각 그림은 시간의 순서를 나타냅니다. 각 그림의 하단부는 noise \(z\)로부터 가짜 이미지 \(x\)로 맵핑하는 것을 나타냅니다. 그리고 상단부에서 검정색 점들의 분포는 실제 이미지의 분포를, 초록색 실선은 Generative model \(G\)가 만들어낸 가짜 이미지의 분포를 나타냅니다. 시간이 흐름에 따라 (학습이 이루어짐에 따라) 점차 초록색 실선이 실제 분포에 fitting되는 것을 확인할 수 있습니다.
파란색 점선은 Discriminative model \(D\)의 예측 결과입니다. 처음에는 아무렇게나 응답하다가, 점점 진짜와 가짜를 구별 잘 하더니, 마지막 (Generative model \(G\)가 완벽해진 순간)에는 모든 예측 확률을 \(\frac{1}{2}\)로 내놓는 것을 확인할 수 있습니다.
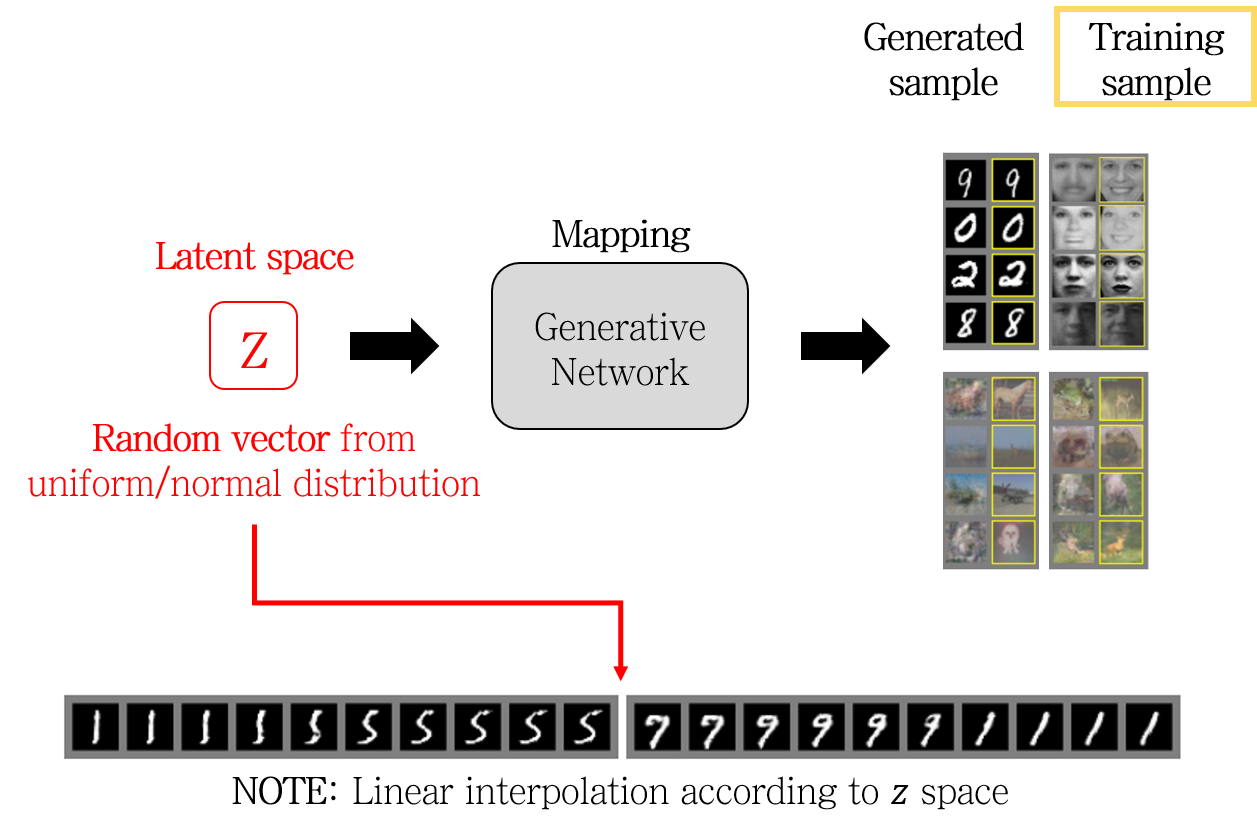
Generative model 부분을 다시 정리해보면 이렇게 됩니다.
단순한 MNIST부터 얼굴 이미지, CIFAR-10 이미지까지, GAN을 통해 Training sample과 거의 비슷한 Generaed sample을 얻은 것을 확인할 수 있습니다.
여기서 한 가지 더 주목할 것은 하단의 Linear interpolation입니다. latent space \(z\)에서 interpolation (보간법)을 진행하면 생성된 결과물이 부드럽게 이어지는 것을 확인할 수 있습니다. 즉, latent space에 따른 mapping이 단순히 1:1 mapping을 기억하고 있는 것이 아니라는 것을 알 수 있습니다.
Limiation

GAN은 초기 모델인만큼, 한계점이 명확합니다. 일단 뭔가 비슷한게 생성되는 것 같긴 한데, 아직은 좀 부족한 느낌이 강합니다. 실제로 MNIST와 같이 단순한 이미지는 잘 생성하지만, 동물같이 복잡한 이미지는 만들어내기 힘들어 하는 것을 볼 수 있습니다.
하지만 이보다 더 큰 문제는, 학습의 안정성이 떨어진다는 점이었습니다.

GAN이 갖는 불안한 안정성의 대표적인 예시로 Mode collapse가 있는데, 이는 학습의 다양성이 떨어지는 것을 말합니다. 즉, 지폐 위조범의 예시에서 한 번 진짜라고 여겨진 위조지폐가 있다면, 다양한 지폐를 만들지 않고 이 지폐만 대량 생산해버리는 것을 생각하면 됩니다.
DCGAN
DCGAN은 Alec Radford (OpenAI), Luke Metz (Google Brain), Soumith Chintala (FAIR) 이 2015년 제안한 GAN 구조입니다.
저자들의 커리어가 화려하네요 .. 부럽다.
가장 큰 특징은 Deep convolutional GAN 이라는 이름에서 느껴지듯, GAN에서는 Fully-connected layer 구조였던 네트워크들을 Convolutional layer 구조로 전부 치환해버렸다는 점입니다.
성능뿐 아니라, 평가를 위한 시각화 방법들을 제시해서 이후 GAN 모델들의 베이스라인으로 사용되고 있습니다.
paper (2015)

DCGAN은 2015년에 Unsupervised Representative Learning With Deep Convolutional Generative Adversarial Networks 라는 논문으로 발표되었습니다.
Key concept

핵심 아이디어는 Generative model \(G\)와 Discriminative model \(D\)의 네트워크 구조에 있습니다. 수많은 실험을 통해 최적의 구조를 가이드라인으로 제시했다고 하는데, 내용은 위와 같습니다.
- 모든 Pooling layer를 convolutional layer로 교체 (\(G\): Fractional-strided convolutions, \(D\): Strided convolutions
- 일반적인 Convolutional layer의 stride 값은 1
- Fractional-strided convolutions: stride를 1보다 작은 분수로 두어, 결과적으로 출력의 크기가 커지는 효과
- Strided convolutions: stdied를 1보다 큰 값으로 두어, 결과적으로 pooling layer처럼 출력의 크기가 작아지는 효과
- \(G\)와 \(D\) 모두에 Batchnorm을 사용
- 모든 Fully-connected layer를 제거
- \(G\)는 출력을 제외한 레이어에 ReLU activation function 사용
- \(D\)는 모든 레이어에 LeakyReLU 사용
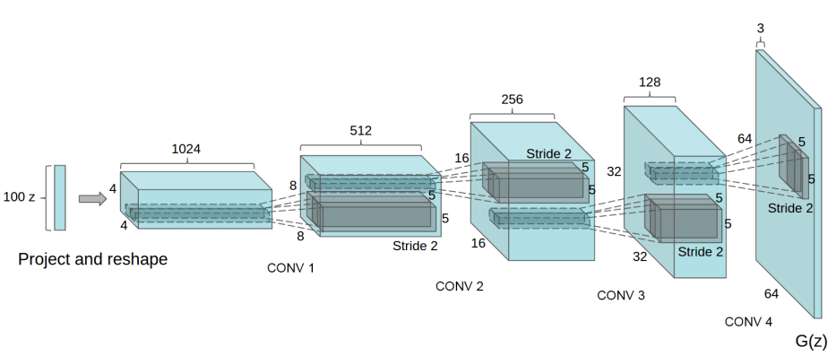
\(G\) 모델의 구조는 위와 같습니다. Convolutional layer에 stride=2가 적용되어 출력의 크기가 커진 것을 확인할 수 있습니다.
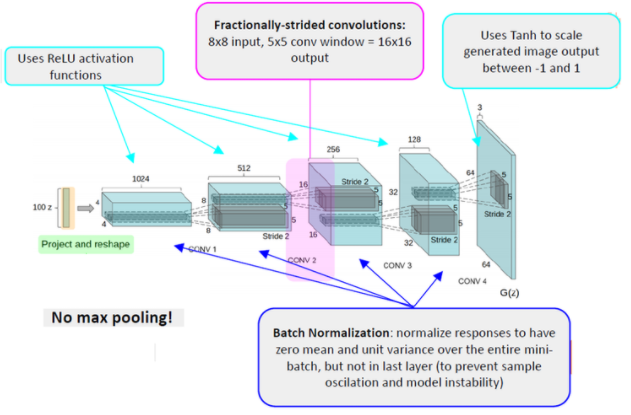
가이드라인에 따라 그림을 뜯어보면 위와 같습니다. (이미지 출처)
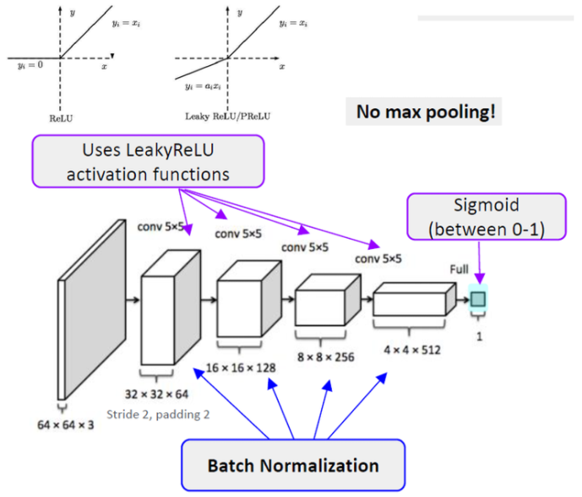
논문에는 나와있지 않지만, \(D\)모델은 이렇게 되겠지요. (이미지 출처)
Results

침실 사진으로 이루어진 LSUN (Large-scale Scene Understanding) 데이터셋으로 DCGAN 모델을 학습시켜본 결과입니다. 이 사진에서 주목할 점은, 이 결과가 단지 1 Epoch을 거친 이미지라고 합니다. 디테일하게 보면 뭉그러진 부분이 좀 있긴 하지만, 그런대로 봐줄만한 이미지를 얻은 것을 확인할 수 있습니다.
1Epoch만 거친 결과이기 때문에 학습 이미지에 대한 과적합 (overfitting)이 일어날 수 없으므로 네트워크가 단지 1:1 맵핑 결과를 기억하고 있는 것이 아니라, 맵핑 함수를 만들어냈다고 볼 수 있습니다.

5 Epoch으로 학습을 진행시키면 더 그럴듯한 이미지를 생성합니다.
Visualization
DCGAN은 안정적인 학습이 가능한 GAN 구조를 제안한 것 이외에도, 몇 가지 기여점이 있습니다.
-
Interpolation: Walking

latent space \(z\)에서 interpolation을 하면 결과 이미지가 자연스럽게 변하는 것을 확인할 수 있습니다. 논문에서는 이 과정을 Walking in the latent space라고 표현하였습니다. 특히 마지막 행을 보면 TV였던 곳이 창문으로 변하는 것을 확인할 수 있습니다.
Discriminative feature

DCGAN 논문에서는 또한 discriminator가 학습한 filter들이 각각 이미지의 어떤 부분을 학습했는지를 보여주어, black box문제를 조금이나마 풀고자 했습니다.
Vector arithmetic
마지막으로, 개인적으로 논문 내용 중 가장 신기했던 내용입니다. 바로 산술 연산이 가능하다는 점입니다.
Vector arithmetic이라는 것은, 이미지의 내용 중 일부분을 가감 가능하다는 것입니다. 예시를 보겠습니다.

웃는 여자의 사진 - 평범한 여자의 사진 + 평범한 남자의 사진을 계산하면, 웃는 남자의 사진이 됩니다.

같은 방식으로, 안경을 쓴 남자의 사진 - 평범한 남자의 사진 + 평범한 여자의 사진을 계산하면 안경을 쓴 여자의 사진이 됩니다.

물론 이 과정은 단순히 pixel간 계산을 통해서는 절대 이루어질 수 없고, latent space \(z\)에서의 산술연산을 통해 이루어집니다. \(z\) 또한 개별적으로 연산을 해서는 잘 안되고, 평균 \(\bar{z}\)을 구해서 연산해야 잘 생성된다고는 합니다.
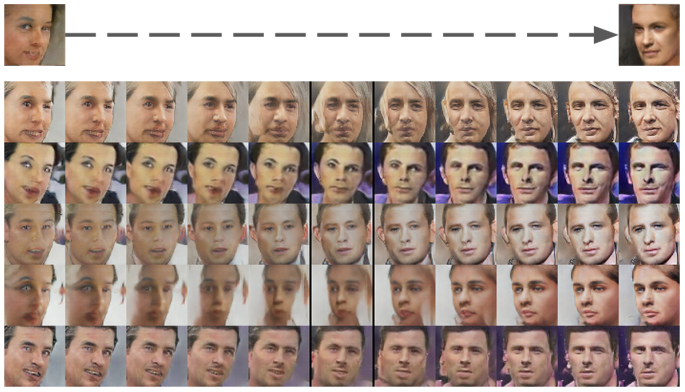
Interpolation과 vector arithmetic을 좀더 활용하면, 이런 표현도 가능합니다.
양쪽을 바라보는 두 얼굴 사진을 interpolation하게 되면, 사진의 얼굴들이 회전하는 효과를 줍니다. 즉, 네트워크가 “회전”이라는 개념을 알고 있는 것이라고 할 수 있습니다.
다음 포스팅에서는 GAN과 DCGAN을 직접 구현해보고자 합니다.
다음 글 보기: Generative Adversarial Nets (GAN) 2: GAN을 PyTorch로 구현해보기
Leave a comment