
Generative Adversarial Nets (GAN) 2: GAN을 PyTorch로 구현해보기
이전 글 보기: Generative Adversarial Nets (GAN) 1: GAN과 DCGAN 설명
이전 포스팅에서는 Generative Adversarial Network의 기본 알고리즘인 GAN과 DCGAN을 정리했습니다.
이번 포스팅에서는 PyTorch를 이용해 GAN 모델을 직접 구현해보도록 하겠습니다.
구성
본 구현에서는 단순한 이미지셋인 MNIST를 사용하여 GAN을 학습시키고자 합니다. GAN 모델은 Generative model \(G\)과 Discriminative model \(D\)를 번갈아가면서 업데이트해나갑니다.
본 포스트의 구성은 아래와 같습니다.
- Load libraries
- MNIST dataset download
- Random sample \(z\) from normal distribution
- Generative model \(G\)
- Disciminative model \(D\)
- Train model \(G\) and \(D\)
- Initialize model \(G\) and \(D\)
- Loss functions & Optimizers
- Train models
- Save model weights
- Visualization (Interpolation)
전체 코드는 Github에서 볼 수 있습니다.
구현
1. Load libraries
GAN 구현에 사용될 라이브러리들을 불러옵니다.
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
import torchvision
import torchvision.utils as utils
import torchvision.datasets as dsets
import torchvision.transforms as transforms
본 구현에 사용된 라이브러리 환경은 아래와 같습니다 (python=3.5)
print('numpy: ' + np.__version__)
print('pandas: ' + pd.__version__)
print('matlotlib: ' + matplotlib.__version__)
print('torch: ' + torch.__version__)
print('torchvision: ' + torchvision.__version__)
numpy: 1.16.0
pandas: 0.25.3
matlotlib: 3.0.3
torch: 1.5.1
torchvision: 0.6.1
결과 재현을 위해 random seed를 설정합니다.
import random
# Set random seed for reproducibility
manualSeed = 2020
#manualSeed = random.randint(1, 10000) # use if you want new results
print("Random Seed: ", manualSeed)
random.seed(manualSeed)
torch.manual_seed(manualSeed);
GPU를 사용할지 선택합니다. 사용 가능한 GPU가 있다면 device 변수에 cuda가, 없다면 cpu가 표시됩니다.
is_cuda = torch.cuda.is_available()
device = torch.device('cuda' if is_cuda else 'cpu')
print(device)
cuda
2. MNIST dataset download
하이퍼파라미터 batch_size 를 설정합니다.
# hyper-parameter
batch_size = 64
MNIST 전처리를 위한 standardize를 설정합니다.
# standardizer
standardizer = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=0,
std=1)])
MNIST 데이터를 다운로드받습니다.
# MNIST dataset
train_data = dsets.MNIST(root='../data/', train=True, transform=standardizer, download=True)
batch_size 단위로 이미지를 로드하기 위한 dataloader를 정의합니다.
train_data_loader = torch.utils.data.DataLoader(train_data, batch_size, shuffle=True)
제대로 로드가 되는지 확인하기 위해, 몇 개의 이미지를 시각화해봅니다.
# function for visualization
def tc_imshow(img, lbl=""):
if img.size(0) == 1:
plt.imshow(img.squeeze(), cmap='gray')
else:
plt.imshow(np.transpose(img, (1, 2, 0)))
plt.title(lbl)
plt.axis('off')
# visualize
mini_batch_img, mini_batch_lbl = next(iter(train_data_loader))
plt.figure(figsize=(4,5))
for i in range(16):
plt.subplot(4,4,i+1)
tc_imshow(img=mini_batch_img[i],
lbl=train_data.classes[mini_batch_lbl[i].numpy()])
plt.axis('off')
plt.savefig('../result/GAN/1-GAN/1-dataloader-example.png', dpi=300)

3. Random sample \(z\) from normal distribution
하이퍼파라미터 dim_noise를 정의합니다. dim_noise는 latent space \(z\)의 차원을 의미합니다.
# hyper-parameter
dim_noise = 100
latent space \(z\)를 생성합니다. \(z\)는 normal distribution으로부터 random sampling됩니다.
# Random sampling from normal distribution
def random_sample_z_space(batch_size=1, dim_noise=100):
return torch.randn(batch_size, dim_noise, device=device)
4. Generative model \(G\)
하이퍼파라미터 dim_hidden, sz_output, num_channels를 정의합니다.
dim_hidden: 네트워크의 hidden layer 채널 수sz_output: 최종 출력 이미지의 width, height 길이 (pixels)num_channels: 인풋 이미지의 채널 수
하이퍼파라미터 값에 따라 dim_output과 img_shape 변수가 정해집니다.
# hyper-paremeters
dim_hidden = 256
sz_output = 28
num_channels = 1
dim_output = sz_output**2
img_shape = (num_channels, sz_output, sz_output)
Generator 구현체를 class로 정의합니다. 구현체로 정해주게 되면, 처음 선언될 때 __init__(self)이 실행되며, z를 인풋으로 받을 때, forward(self, z)가 실행됩니다.
일반적으로 __init__(self) 함수에서 네트워크 구조를 정의합니다. 네트워크 구조는 fully-connected layer로 구성합니다.
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(dim_noise, dim_hidden),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(dim_hidden, dim_hidden),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(dim_hidden, dim_output),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), *img_shape)
return img
\(G(z)\)의 이미지를 그려봅니다. 아직 generator \(G\)가 학습되지 않은 상태이기 때문에, nosiy한 이미지만 출력됩니다.
# visualize
utils.save_image(G(z)[:25].cpu().detach(), "../result/GAN/1-GAN/2-G(z).png", nrow=5, normalize=True)
.png)
5. Disciminative model \(D\)
Discriminative model \(D\)의 형태는 \(G\)를 거꾸로 뒤집은 형태입니다. \(G\)의 MLP 구조를 거꾸로 구성해줍니다. \(D\)의 출력 레이어는 입력으로 받은 이미지가 진짜인지 가짜인지 판단하는 sigmoid function을 이용합니다.
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(dim_output, dim_hidden),
nn.LeakyReLU(0.2),
nn.Dropout(0.1),
nn.Linear(dim_hidden, dim_hidden),
nn.LeakyReLU(0.2),
nn.Dropout(0.1),
nn.Linear(dim_hidden, 1),
nn.Sigmoid()
)
def forward(self, img):
flat_img = img.view(img.size(0), -1)
check_validity = self.model(flat_img)
return check_validity
6. Train model \(G\) and \(D\)
6.1 Initialize model \(G\) and \(D\)
Generative model과 Discriminative model을 선언합니다.
generator = Generator().to(device)
discriminator = Discriminator().to(device)
6.2 Loss functions & Optimizers
하이퍼파라미터 learning_rate를 정의합니다.
learning_rate: optimizer에 사용되는 learning rate입니다.beta1: Adam optimizer에 사용되는 momentum parameter입니다.
# hyper-parameter
learning_rate = 0.0002
beta1 = 0.9
Loss function은 Binary Cross Entropy (BCE)를 사용합니다. PyTorch 내장함수인 ``torch.nn.BCELoss()`를 이용합니다.
adversarial_loss = nn.BCELoss()
optimizer는 각 모델별로 정의합니다. Adam optimizer를 사용합니다.
optimizer_G = optim.Adam(generator.parameters(), lr=learning_rate, betas=(beta1, 0.999))
optimizer_D = optim.Adam(discriminator.parameters(), lr=learning_rate, betas=(beta1, 0.999))
6.3 Train models
하이퍼파라미터 num_epochs와 interval_save_img를 정의합니다.
num_epochs: 최대 Epoch 수를 의미합니다.interval_save_img: 이미지 생성 결과를 저장할 인터벌을 정의합니다. 일정 batch size마다 이미지가 저장되어 생성모델의 학습과정을 확인할 수 있습니다.
# hyper-parameters
num_epochs = 200
interval_save_img = 1000
FloatTensor모델을 정의합니다. 연산 시 변수들의 데이터 타입을 맞춰주기 위함입니다.
Tensor = torch.cuda.FloatTensor if is_cuda else torch.FloatTensor
\(G\), \(D\) 모델에 num_epochs만큼 데이터셋을 학습시킵니다. batch_size개씩 입력으로 들어갑니다.
전체적인 순서는 아래와 같습니다.
- 진짜 이미지 정의
- 가짜 이미지 생성
- 가짜 이미지와 real값 사이의 loss 계산 (
loss_G) loss_G로 Generator \(G\) weight 업데이트- 진짜 이미지와 fake값 사이의 loss 계산 (
loss_real) - 가짜 이미지와 real값 사이의 loss 계산 (
loss_fake) loss_D계산 (loss_real과loss_fake의 평균값)loss_D로 Discriminator \(D\) weight 업데이트- 학습상태 print
interval_save_img에 따라 생성 이미지 저장
losses = []
for idx_epoch in range(num_epochs):
for idx_batch, (imgs, _) in enumerate(train_data_loader):
# Ground truth variables indicating real/fake
real_ground_truth = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)
fake_ground_truth = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)
# Real image
real_imgs = Variable(imgs.type(Tensor))
#####################
# Train Generator
optimizer_G.zero_grad()
# Random sample noise
z = random_sample_z_space(imgs.size(0))
# Generate image
gen_imgs = generator(z)
# Generator's loss: loss between D(G(z)) and real ground truth
loss_G = adversarial_loss(discriminator(gen_imgs), real_ground_truth)
loss_G.backward()
optimizer_G.step()
#####################
# Train Discriminator
optimizer_D.zero_grad()
loss_real = adversarial_loss(discriminator(real_imgs), real_ground_truth)
loss_fake = adversarial_loss(discriminator(gen_imgs.detach()), fake_ground_truth)
loss_D = (loss_real+loss_fake)/2
loss_D.backward()
optimizer_D.step()
#####################
# archieve loss
losses.append([loss_G.item(), loss_D.item()])
# Print progress
if idx_batch % 10 == 0:
print("[Epoch {}/{}] [Batch {}/{}] loss_G: {:.6f}, loss_D: {:.6f}".format(idx_epoch, num_epochs,
idx_batch, len(train_data_loader),
loss_G, loss_D))
batches_done = idx_epoch * len(train_data_loader) + idx_batch
if batches_done % interval_save_img == 0:
utils.save_image(gen_imgs.data[:25], "../result/GAN/1-GAN/3-{}.png".format(batches_done), nrow=5, normalize=True)
0 → 1000 → 10000 → 100000번째 batch 학습 결과입니다 (
batch_size=64). Generative model이 점차 학습되어 가는 것을 확인할 수 있습니다.




200 epoch에 대한 이미지 생성 결과를 시각화해봅니다.
# Random sample noise
z = random_sample_z_space(batch_size)
# Generate image
gen_imgs = generator(z)
# visualize
utils.save_image(gen_imgs.data[:25].cpu().detach(), "../result/GAN/1-GAN/4-fake-images.png", nrow=5, normalize=True)

6.4 Save model weights
학습된 가중치를 저장해둡니다.
torch.save({
'epoch': num_epochs,
'model_G_state_dict': generator.state_dict(),
'model_D_state_dict': discriminator.state_dict(),
'optimizer_G_state_dict': optimizer_G.state_dict(),
'optimizer_D_state_dict': optimizer_D.state_dict()
}, '../result/GAN/1-GAN/model_weights.pth')
7. Visualization (Interpolation)
Interpolation 그림을 그려봅시다.
학습이 완전하지는 않기 때문에, 사이드 그림이 깔끔한 것을 먼저 골라냅시다.
z_opposites = random_sample_z_space(2)
fake_img = generator(z_opposites)
plt.subplot(121); plt.imshow(fake_img[0].squeeze().cpu().detach(), cmap='gray')
plt.subplot(122); plt.imshow(fake_img[1].squeeze().cpu().detach(), cmap='gray')
plt.savefig('../result/GAN/1-GAN/5-side-images.png', dpi=300)
7과 3이 생성된 것을 확인할 수 있습니다.

두 이미지를 사이드 이미지로 두고, 그 사이의 latent space를 interpolation해봅니다.
num_interpolation = 10
z_interpolation = Variable(Tensor(np.linspace(z_opposites[0].cpu(), z_opposites[1].cpu(), num_interpolation)))
fake_img = generator(z_interpolation)
plt.figure(figsize=(12,2))
for i in range(num_interpolation):
plt.subplot(1,num_interpolation,i+1)
plt.imshow(fake_img[i].squeeze().cpu().detach(), cmap='gray')
plt.axis('off')
plt.savefig('../result/GAN/1-GAN/6-interpolation.png', dpi=300)
interpolation이 잘 되는 것을 확인했습니다. 숫자가 부드럽게 (?) 변하네요.
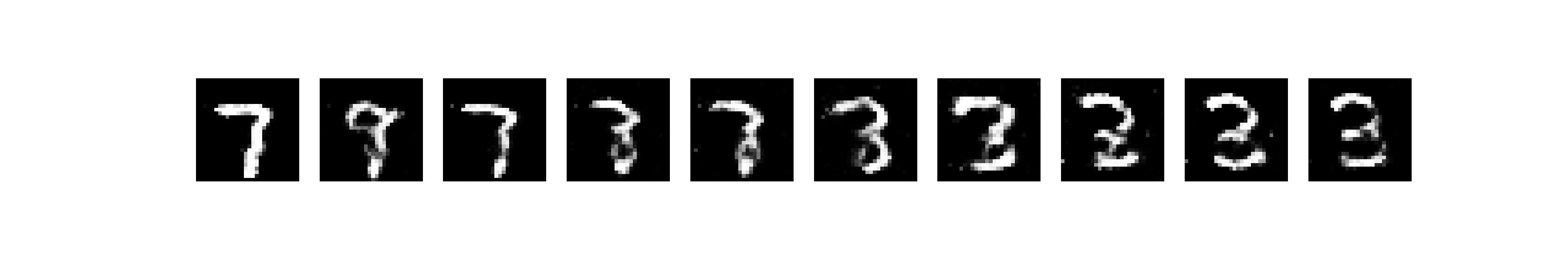
이번 포스팅에서는 GAN의 기본적인 구조를 PyTorch로 구현해보았습니다.
다음 포스팅에서는 DCGAN을 구현해보고자 합니다.
다음 글 보기: Generative Adversarial Nets (GAN) 3: DCGAN을 PyTorch로 구현해보기
Leave a comment