
Classification for MEDIA (5) Overcome small dataset
이전 포스팅: Classification for MEDIA (4) Advanced CNN models
이전 포스팅에서는 주요 CNN 모델들에 대해 정리했습니다.
이번 포스팅에서는 Medical image dataset의 특징인 적은 샘플 수를 극복하기 위한 여러 방법들을 정리해보고자 합니다.
원래 강의에서는 별도로 타이틀을 달지는 않았지만, Validation, Regularization, Transfer learning, Data augmentation 등 이번 주차 강의에서 설명해주신 기법들을 아우를 수 있는 주제일 것 같아 임의로 정했습니다.
Overall procedure for Medical image analysis
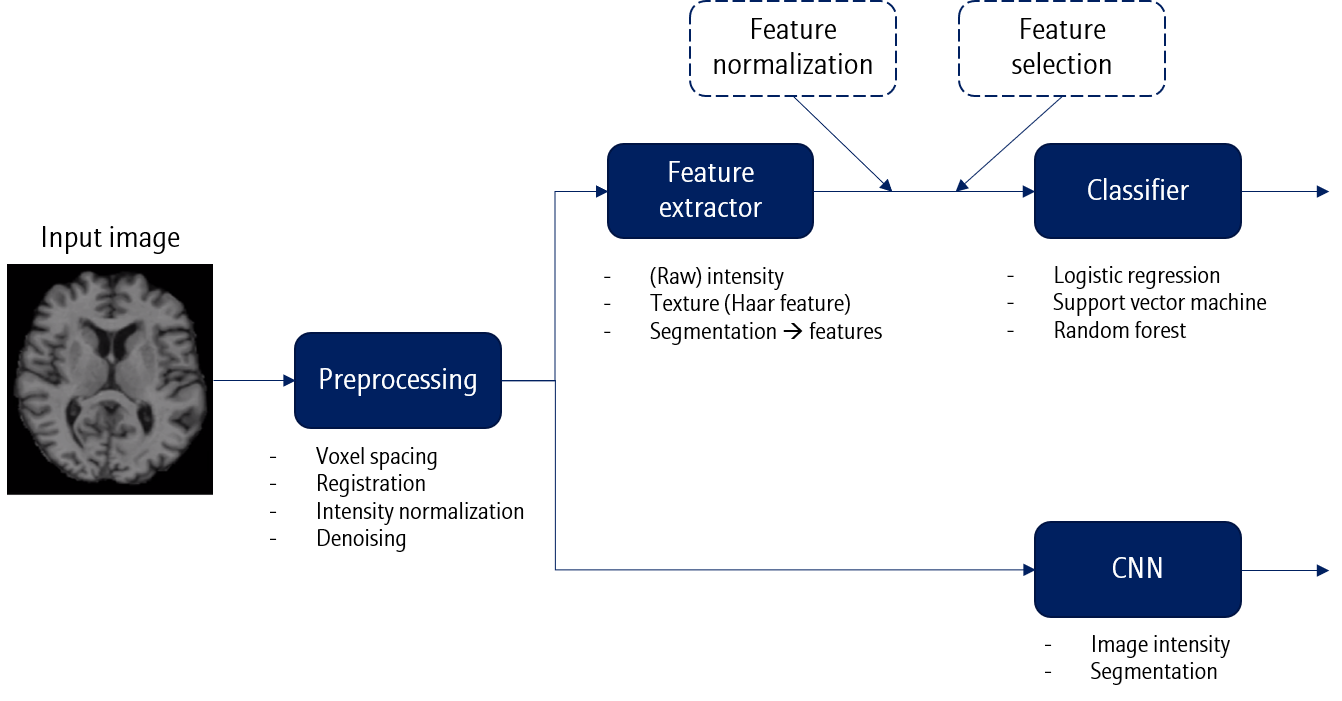
지금까지 배워온 내용을 간단히 정리해봅시다.
2D 또는 3D 의료영상 이미지를 입력으로 받게되면, 가장 먼저 전처리 (Preprocessing) 과정이 진행됩니다. 이 때 voxel spacing, registration, intensity normalization, denoising 등이 사용될 수 있습니다. 이후는 크게 두 갈래로 나뉩니다.
- Feature extractor + Classifier
Feature extractor와 Classifier가 별개로 이루어진 모델입니다.
Feature로는 intensity (raw 값), texture (Haar feature) 등이 사용될 수 있으며, Segmentation 을 통해 특정 ROI로부터 feature를 뽑아 사용할 수도 있습니다.
Classifier에 feature를 바로 사용할 수도 있지만, demographic score를 이용한 feature normalization이나 feature selection 등의 방법을 사용하여 feature를 정제해 사용할 수도 있습니다.
- End-to-end learning
End-to-end learning에서는 deep learning과 같이 feature extractor와 classifier가 합쳐진 모델을 말합니다. 물론 End-to-end learning에서도 위에서 언급한 feature normalization이나 feature selection을 적용하는 것이 가능합니다.
일반적인 이미지 분류 문제와 거의 비슷하지만 의료영상은 데이터 수가 부족하다라는 큰 어려움을 갖습니다. 이를 해결하기 위한 방법을 알아봅시다.
- Validation
- Regularization
- Transfer learning
- Data augmentation
Solutions for small dataset
1. Validation
Validation data는 학습에 필요한 적절한 하이퍼파라미터를 찾거나 학습 종료시점을 찾을 때 활용하는 데이터입니다.

주로 주어진 데이터를 Training / Test가 아닌, Trainig / Validation / Test로 나누어 사용합니다.
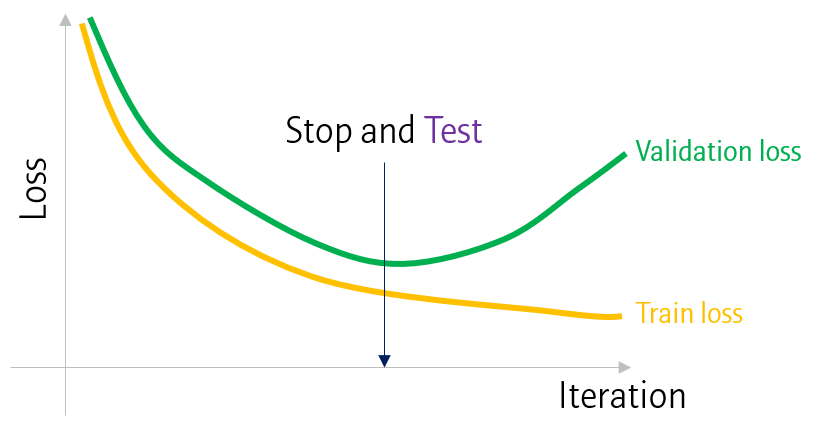
매 Epoch마다 모델 학습 이후, validation 데이터에 대해 loss를 계산합니다. 일반적으로 validation loss가 training loss보다 높습니다. 또한 일정 시점이 지나면 training loss는 계속해서 감소하지만, validation loss는 감소하지 않고 (때때로) 오히려 증가하는 지점이 생깁니다. 이 때를 기점으로 과적합 (overfitting)이 일어난 것으로 생각할 수 있으며, 학습을 종료시키는 지점으로 사용할 수 있습니다.
Cross validation
cross validation은 데이터가 적을 때 사용하는 방법입니다.
k-fold cross validation
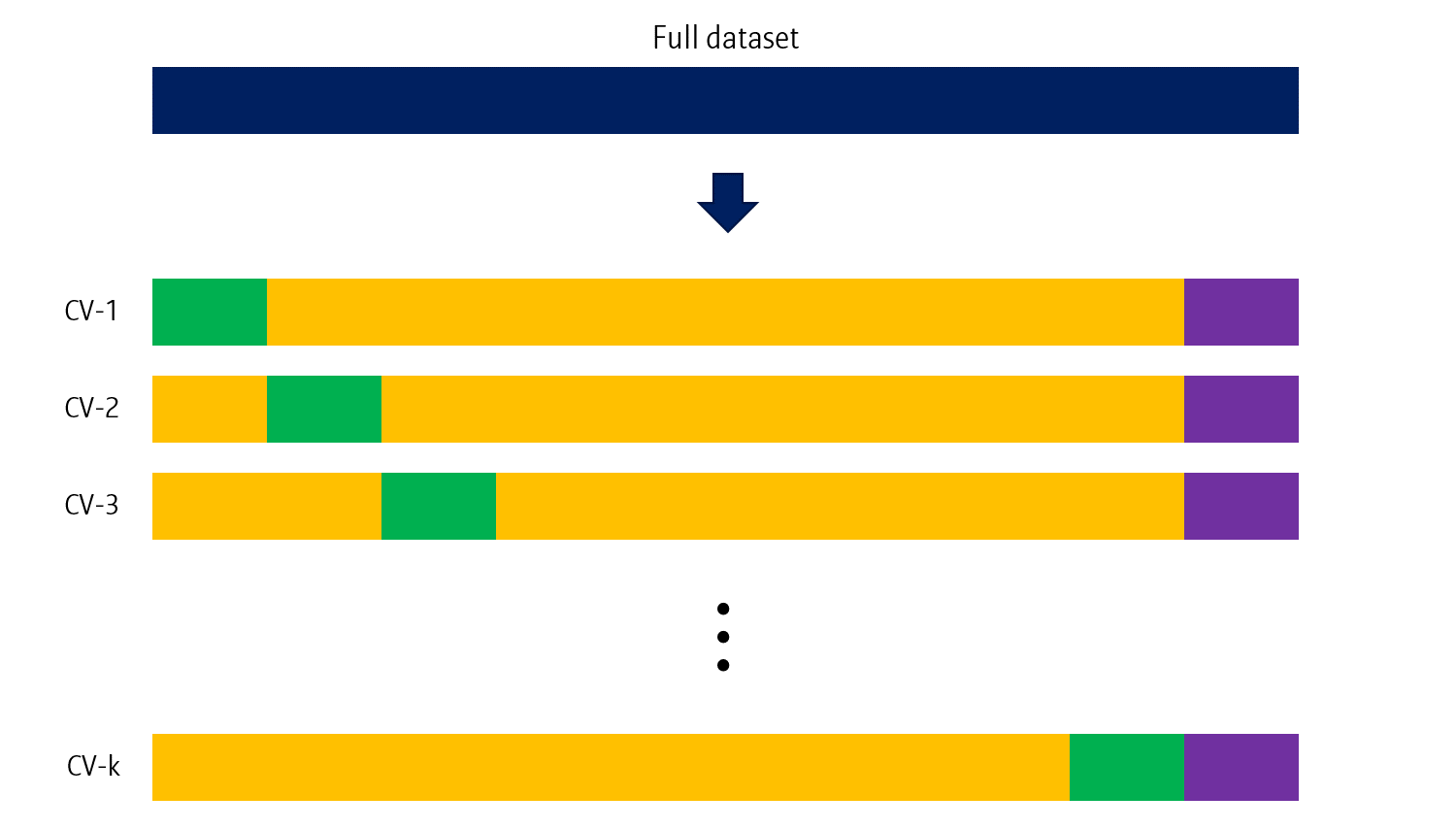
Train data를 k개의 블럭을 나눈 후, 각 블럭을 validation data로 하는 학습을 k번 시행합니다. 학습 종료 후, test data에 대해서도 분류를 수행하며, 최종 결과는 k개의 클래스별 예측확률 평균을 이용해 분류합니다.
Leave-one-out cross (LOO) validation
데이터가 정말 극단적으로 없는 경우에는 Leave-one-out (LOO) cross validation을 사용해볼 수도 있습니다.
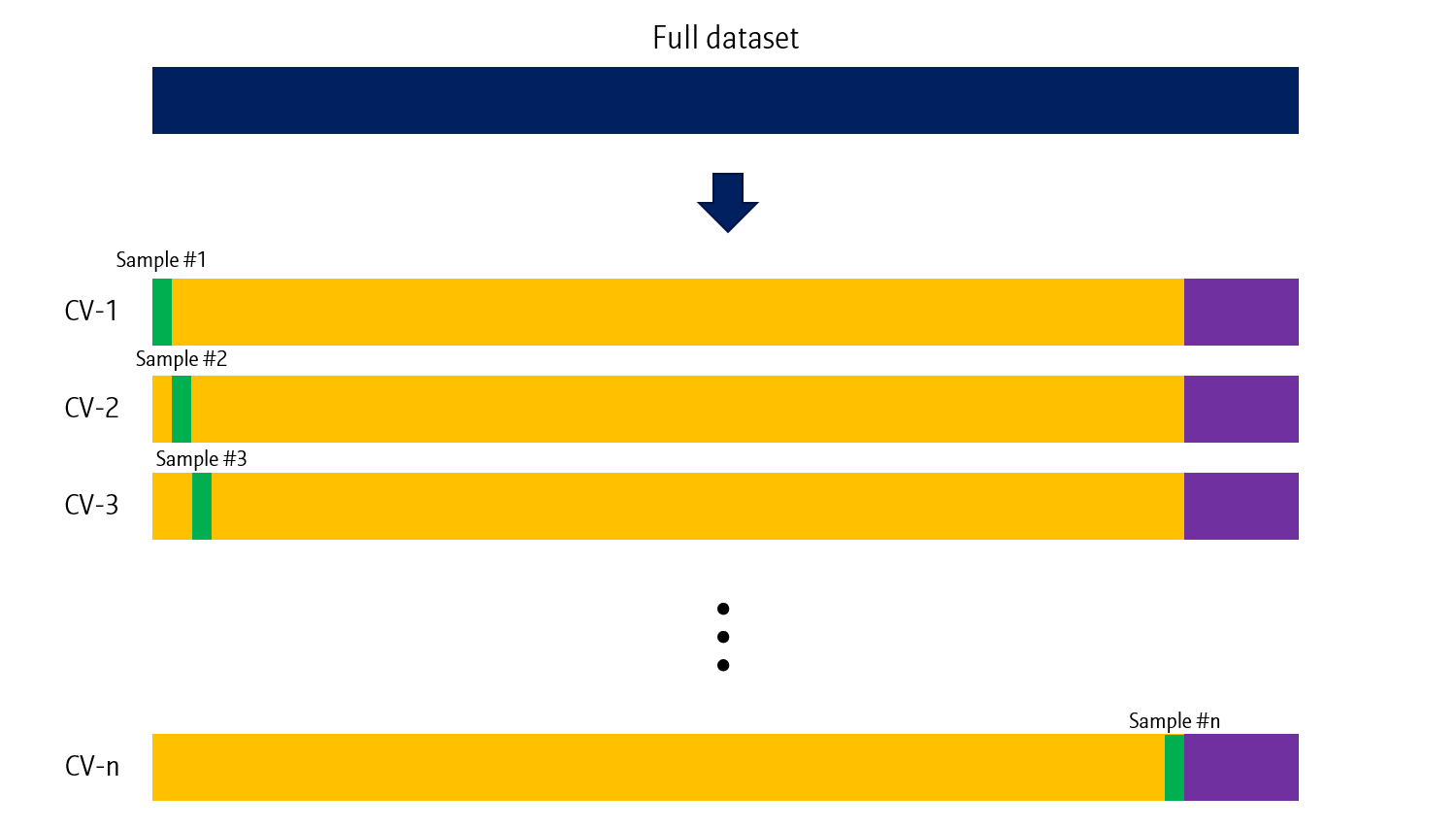
Leave-one-out CV는 말 그대로 한 샘플만을 validation data로 사용하는 과정을 n번 (train data 수) 진행합니다. 학습할 데이터 수가 적기 때문에 validation의 비중을 최소한으로 줄인 cross validaiton이라고 볼 수 있습니다.
Leave-one-subject-out (LOSO) cross validation
특정한 경우 (모델의 피험자에 따른 일반화 성능 검증 등)에는 Leave-one-subject-out (LOSO) CV도 사용합니다.
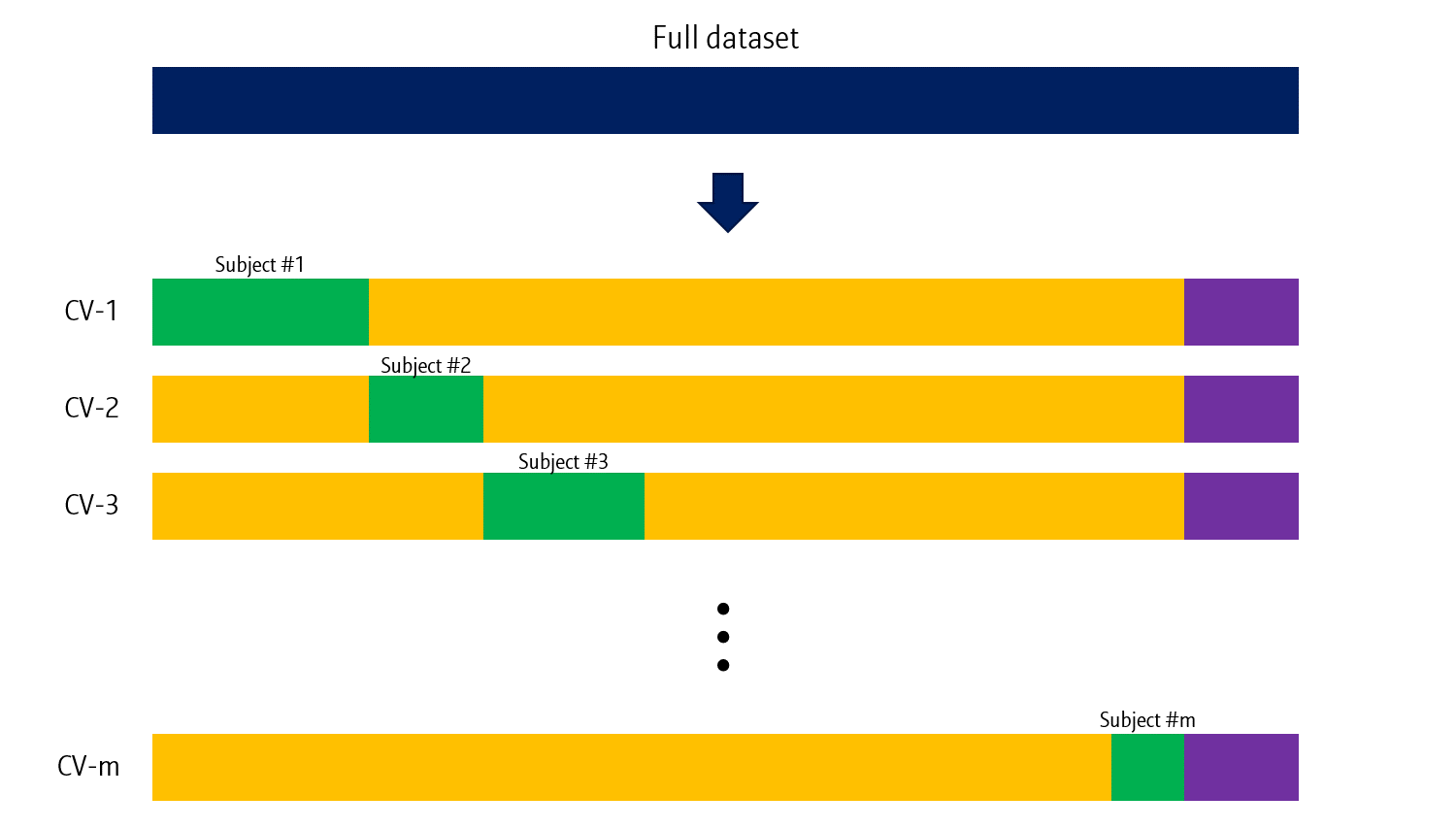
말 그대로 한 subject의 데이터만을 validation으로 사용하는 방법입니다. 앞의 두 방법과 다르게, subject별 데이터 개수에 따라 validation data의 크기가 달라질 수 있습니다. Subject는 목적에 따라 피험자가 될 수도 있고, 특정 조건이 될 수도 있습니다.
2. Regularization
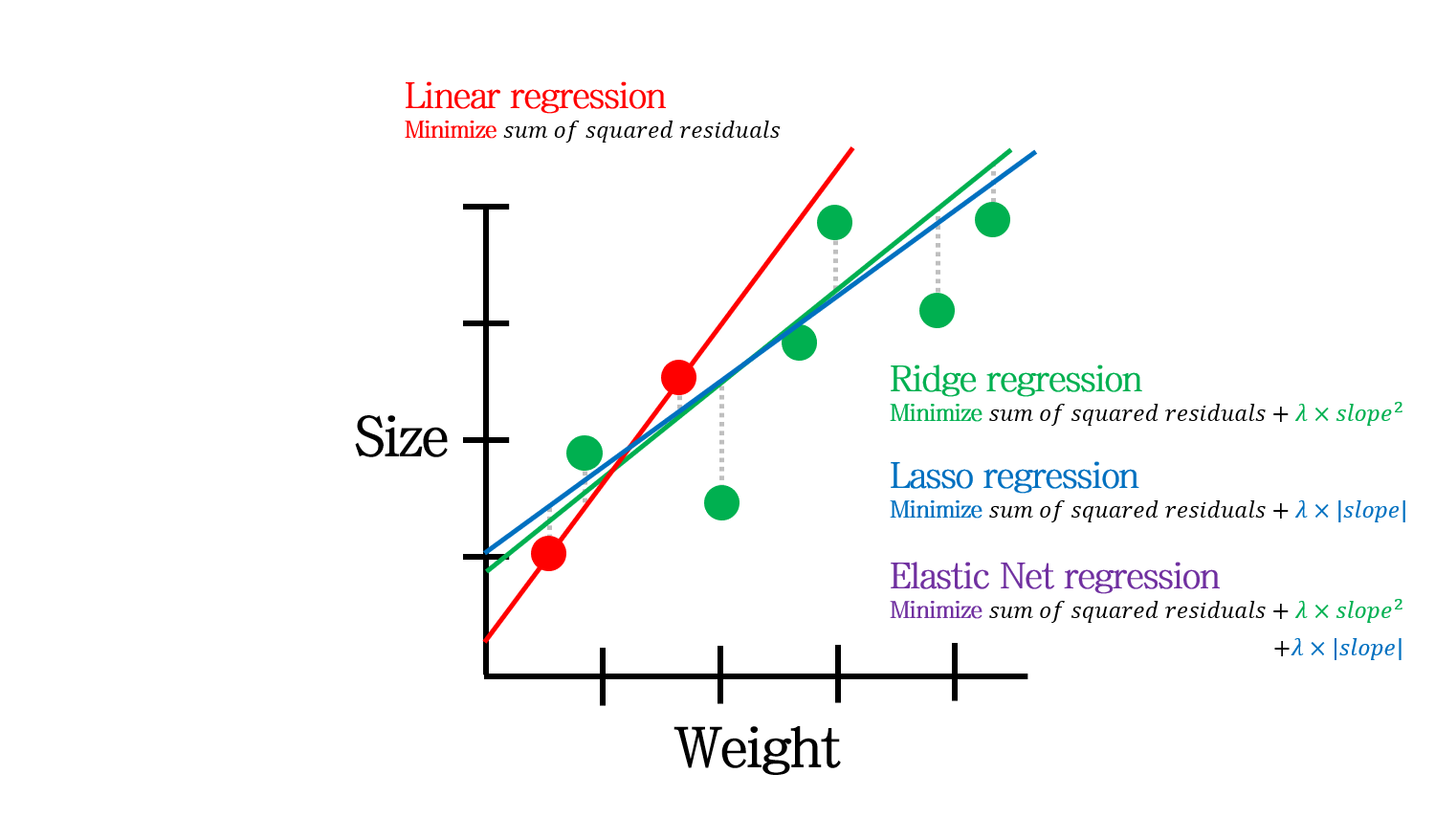
Regularization 또한 데이터수가 적을 때 활용될 수 있습니다.
L1 regularization (Lasso)를 이용하여 feature selection을 합니다. 파라미터 수가 줄어들기 때문에, 조금이나마 overfitting의 위험을 줄여주는 효과가 있습니다.
Regularization이 익숙하지 않다면 아래 포스팅을 참고하세요.
3. Transfer learning
세번째 방법은 Transfer learning (전이 학습) 입니다.

이전 포스팅에서 다룬 좋은 성능을 내는 주요 classification 모델들은 정말 많은 데이터를 기반으로 학습되었습니다. 예를 들어 ImageNet의 경우 1,400만개에 달하는 이미지를 가진 데이터셋입니다.
하지만 앞서 언급했듯, 의료영상데이터는 이에 비해 확연히 적은 수의 데이터를 가집니다. 이런 경우 Transfer learning이 효과적인 방법이 될 수 있습니다.
Procedure
Transfer learning 한 가지 가정이 있습니다.
Pre-trained model에서 학습한 데이터와 Target image (의료 영상)을 구성하는 feature는 동일하다
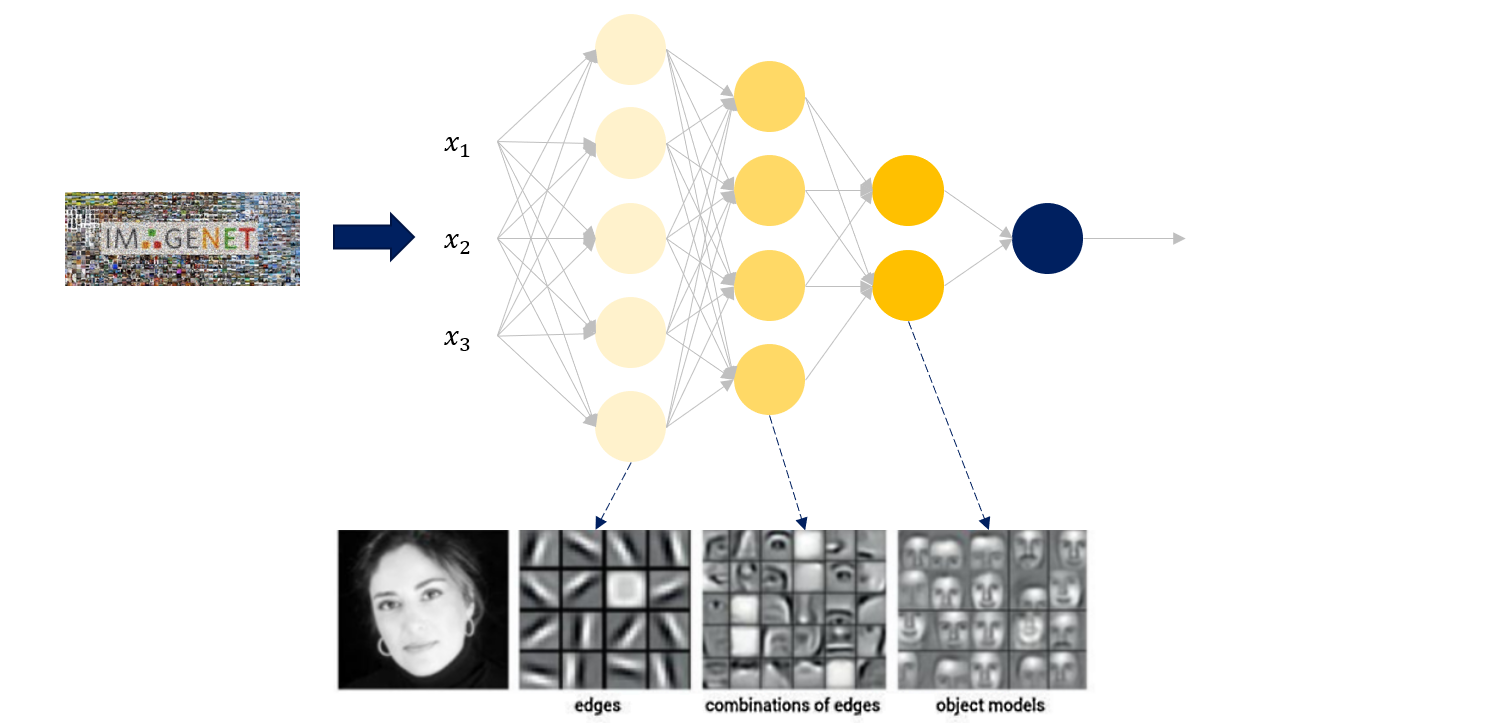
예를 들어, Imagenet을 통해 학습한 모델 (pre-trained model)의 초반 레이어는 edge를, 후반 레이어는 object shgpe을 인식하게 된다고 합시다.
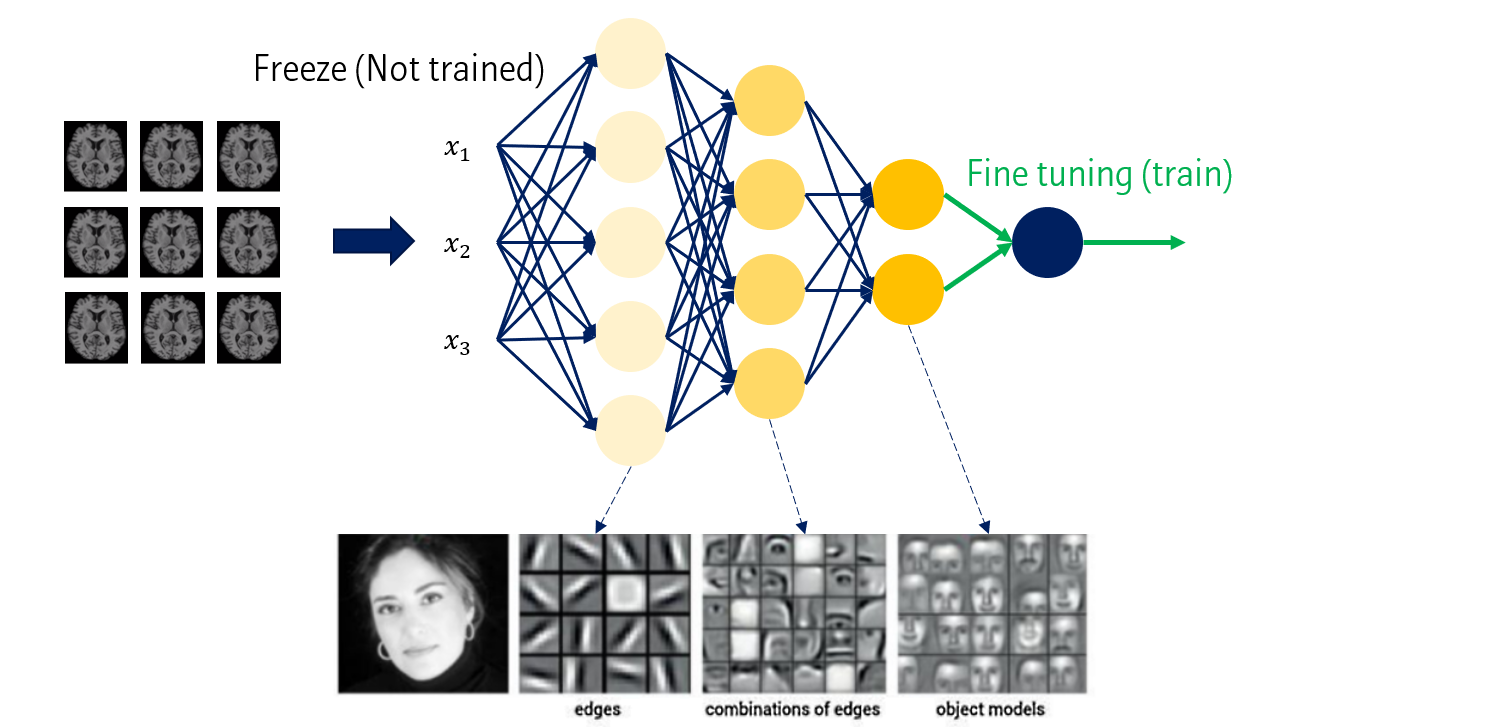
위에서 뽑힌 feature가 의료 영상을 인식하는데도 유효하다는 가정입니다.
따라서, pre-trained model의 구조와 weight를 이용해서 의료영상 분류에 사용할 수 있습니다. 이 때 몇 가지 수정이 필요합니다.
- Input size: Pre-trained model에 적합하도록 입력 사이즈를 정해줄 필요가 있습니다.
- Output class 개수: Pre-trained model들과 출력 class의 개수가 다를 수 있습니다. 이를 수정해주어야 합니다.
- Fine tuning: 학습 이미지와 타겟 이미지가 동일하지 않다보니 추가적인 모델 학습이 필요합니다. Feature를 추출하는 모델의 앞단 weight는 고정시키고 (freeze), 뒷단의 classifier 역할을 하는 레이어들만 추가로 학습시킵니다.
Four types of fine-tuning
Fine tuning은 데이터 유사도와 타겟 데이터 사이즈몇 가지 종류로 나눌 수 있습니다.
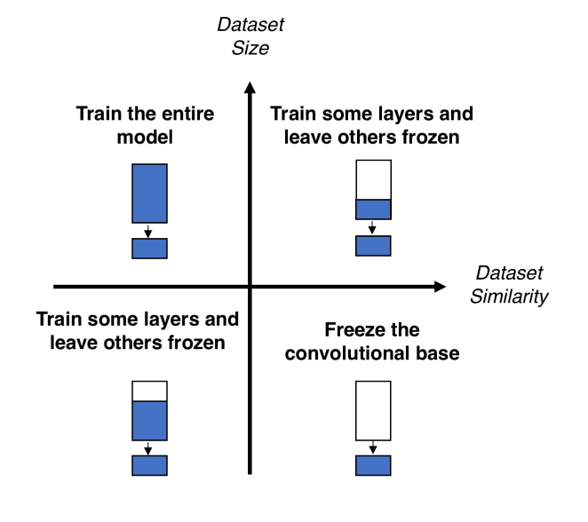
- 타겟데이터가 학습데이터와 유사하고, 양이 많을 경우 (1사분면): Pre-trained feature를 어느 정도 재사용가능하지만, 이왕 데이터가 충분히 있으니 Pre-trained 모델의 Feature extractor 후반부와 Classifier 부분을 학습시킵니다.
- 타겟데이터가 학습데이터와 유사하지 않지만, 양이 많을 경우 (2사분면): Pre-trained feature를 대폭 수정할 필요가 있습니다. 마침 데이터가 많으니, Pre-trained 모델 전체를 추가학습시킵니다.
- 타겟데이터가 학습데이터와 유사하지 않고, 양도 적을 경우 (3사분면): Pre-trained feature를 대폭 수정해야 하기 때문에 모델의 대부분을 추가학습시킵니다. 다만 데이터가 많지 않으니, 초반 일부분은 그대로 둡니다. 왜냐하면 이 레이어들은 edge와 같은 specific한 정보를 담당하기 때문에 domain-independent한 정보를 갖는 경우가 많기 때문입니다.
- 타겟데이터가 학습데이터와 유사하지만, 양이 적을 경우 (4사분면): Pre-trained feature를 그대로 사용할 수 있습니다. 데이터도 적으니, Pre-trained model의 분류기 부분만 최소한으로 추가학습시킵니다.
실제로 많은 경우, 직접 구성하고 학습시킨 모델보다 Pre-trained model의 성능이 좋은 경우가 많습니다.
4. Data augmentation
마지막 방법은 Data augmentation (데이터 증강)입니다. 데이터 수를 강제로 늘려주는 방법입니다.
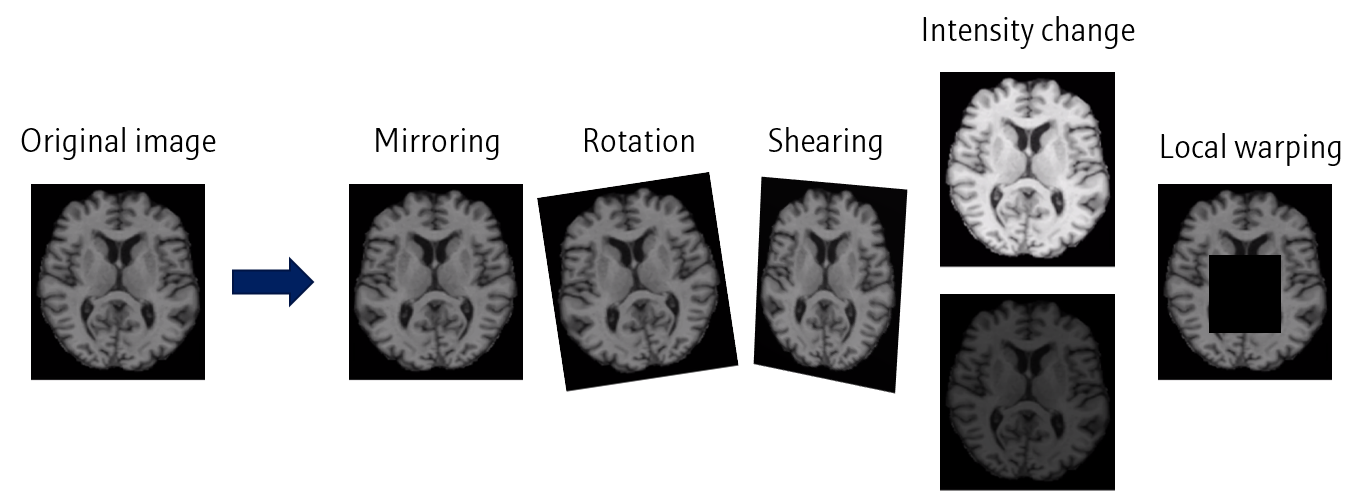
이미지 처리 관련한 데이터 증강 방법들로는 Mirroring, Rotation, Shearing, Intensity change, Local warping 등이 있습니다. 원본 이미지에 약간의 조작을 가해 새로운 이미지들을 생성합니다.
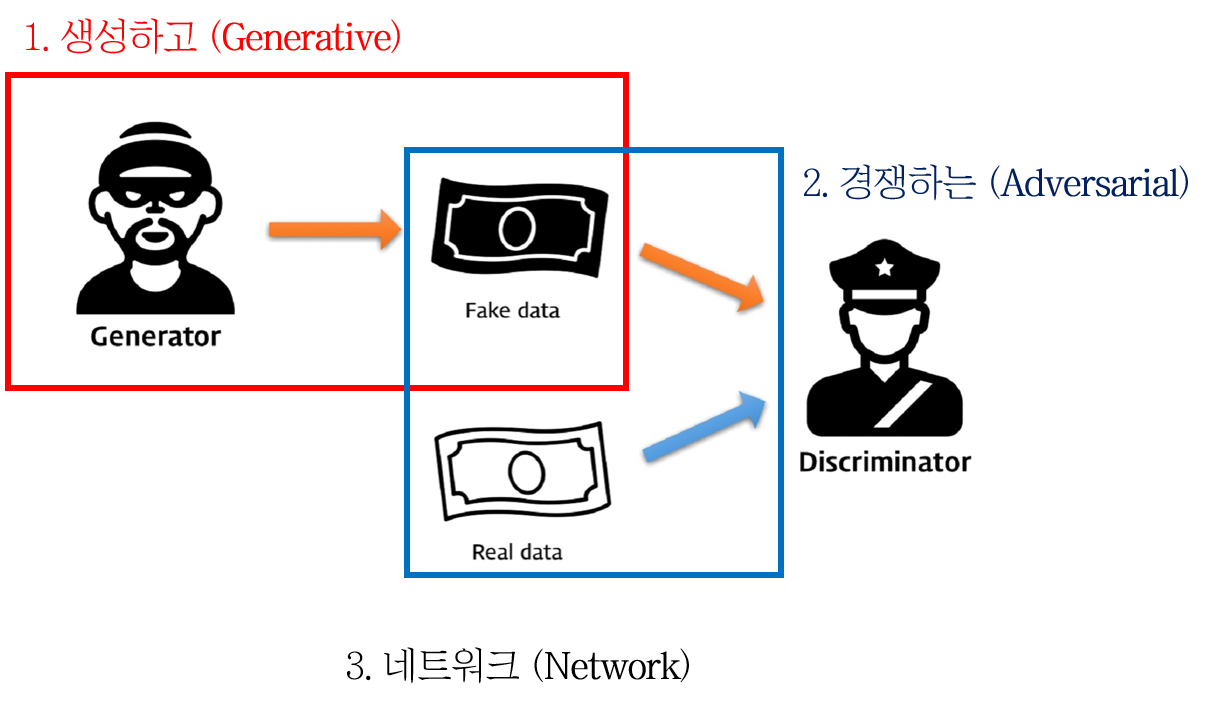
최근에는 Generative adversarial network (GAN)와 같은 Generative model 들을 활용하여 데이터 증강을 하기도 합니다. GAN에 대한 정보는 아래를 참고해주세요.
이번 포스팅에서는 데이터 수가 적은 의료영상 분류 문제를 개선하는 몇가지 방법을 정리했습니다.
다음 포스팅에서는 분류 모델의 평가 방법에 대해 정리하고자 합니다.
다음 포스팅: Classification for MEDIA (6) Evaluation metrics for classification (분류모델 평가 지표)
Leave a comment