
배깅 앙상블 (Bagging Ensemble): Random Forest
이전 글 보기: 앙상블 (Ensemble)의 기본 개념
이전 포스팅에서는 앙상블 (Ensemble)의 기본적인 개념과 그 종류들에 대해 정리했습니다.
이번 포스팅에서는 그 중 배깅 (Bagging) 앙상블의 대표적인 예시인 Random Forest 알고리즘에 대해 정리하겠습니다. 정말 간단합니다.
Random Forest

숲에는 많은 나무들이 있고, 이 나무들은 서로 다른 가지의 개수, 모양, 형태를 가집니다.
이 문장에서 숲을 Random Forest로, 나무를 Decision tree로 바꾸어봅시다.
Random Forest에는 많은 Decision tree들이 있고, 이 Decision tree들은 서로 다른 가지의 개수, 모양, 형태를 가집니다.
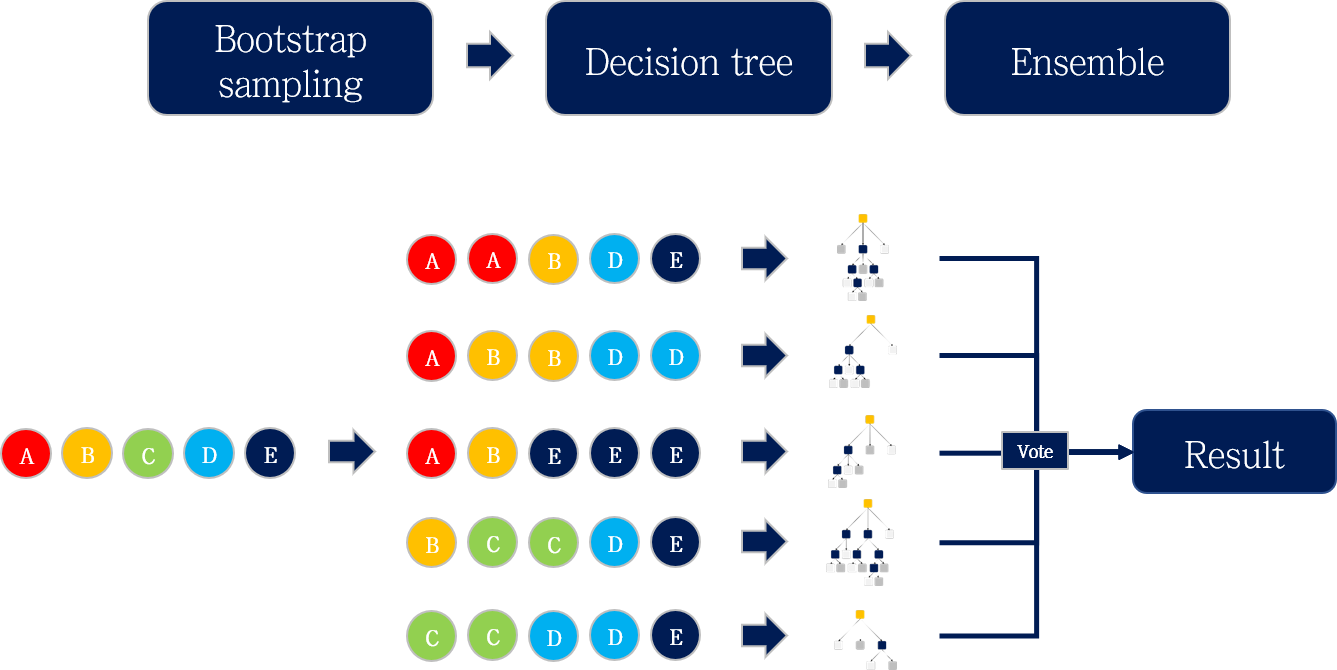
Random Forest는 배깅 (Bagging) 앙상블 알고리즘의 대표적인 예시입니다. Bagging이란 Bootstrap aggregating의 줄임말로, 이름 그대로 Bootstrap 기반의 앙상블 알고리즘입니다.
Random forest의 생성 과정을 세 개의 파트로 나누어 정리했는데, 앞의 포스팅들에서 다 설명한 내용들이라 간단히 설명하겠습니다.
Bootstrap
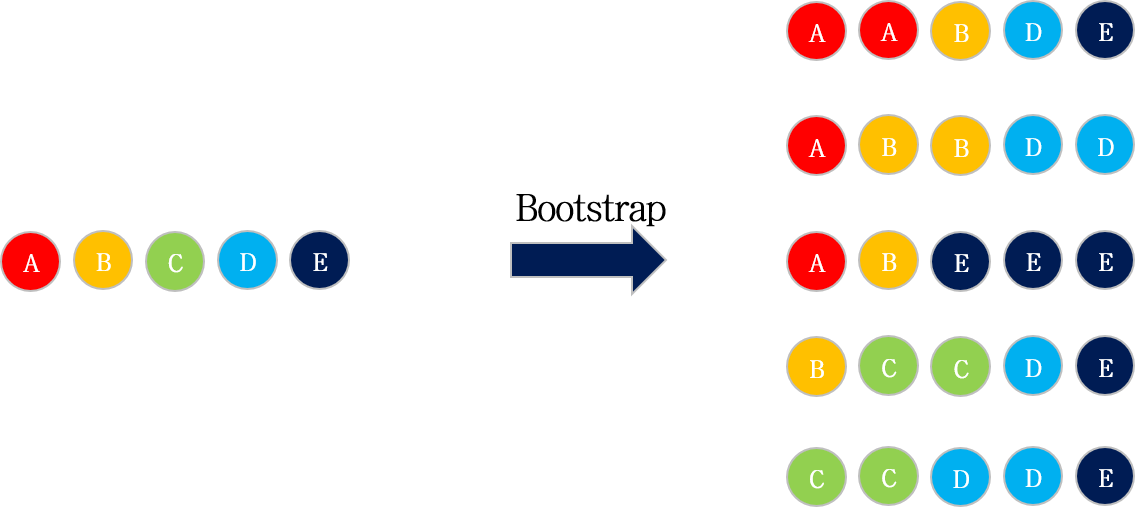
주어진 데이터셋으로부터 Random sampling을 통해 각 decision tree를 만들기 위한 subset을 생성합니다. 이 때, sampling되는 데이터는 중복을 허용합니다.
Decision tree
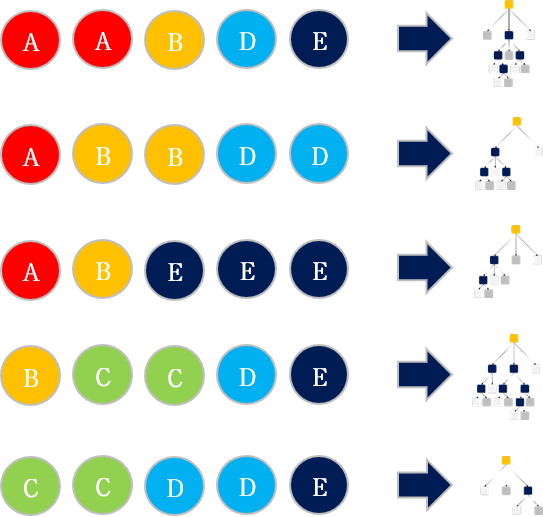
Bootstrap을 통해 생성된 각각의 데이터셋에 대한 Decision tree들을 구성합니다.
Ensemble
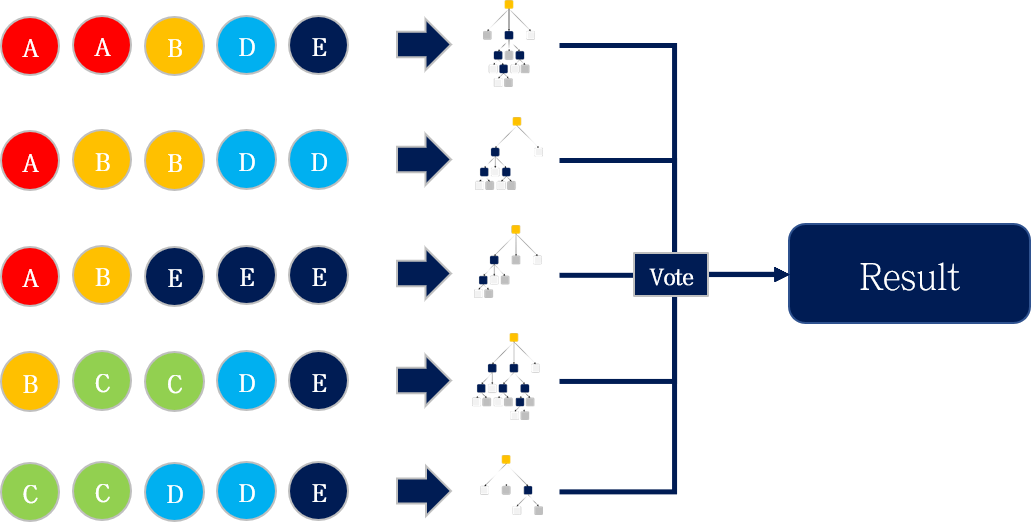
각 Decision tree의 예측 결과를 voting하여 최종 예측값을 얻습니다.
Python code
python scikit-learn 라이브러리의 sklearn.ensemble.RandomForestClassifier 또는 sklearn.ensemble.RandomForestRegressor를 이용해 Random Forest를 사용할 수 있습니다.
# library load
from sklearn.ensemble import RandomForestRegressor
# build model
mdl = RandomForestRegressor()
# fit (training)
mdl.fit(X_trn, y_trn)
# predict (testing)
mdl.predict(X_tst, y_tst)
다음 포스팅부터는 부스팅 (Boosting) 앙상블의 초기 모델인 AdaBoost 알고리즘에 대해 정리해보겠습니다.
Leave a comment