
의사결정 나무 (Decision Tree) 기본 설명
본 포스팅에서는 기계 학습 (Machine learning)의 대표적인 알고리즘 중 하나인 의사결정 나무 (Decision tree) 알고리즘에 대해서 다뤄보고자 합니다.
Motivation
의사결정 나무는 개념이 워낙 간단한 알고리즘이고, 최근 들어 워낙 심층 학습 (Deep learning)이 대세로 굳어지다보니 ‘이걸 굳이 자세히 공부해야하나?’ 라는 생각을 갖고 있던 알고리즘이었는데, 최근 Kaggle과 같은 데이터 분석 대회에 관심을 갖게 되면서 공부할 필요성을 느끼게 되었습니다.
2019년 4월, Keras library의 개발자 중 한 명인 François Chollet의 tweet에 올라온 내용입니다.
Kaggle competition 상위권 팀들의 알고리즘을 종합해본 결과, 2, 3위를 딥러닝 기반이 아닌 Gradient Boosting Decision Tree (GBDT) 기반 Ensemble 모델이 차지했습니다.
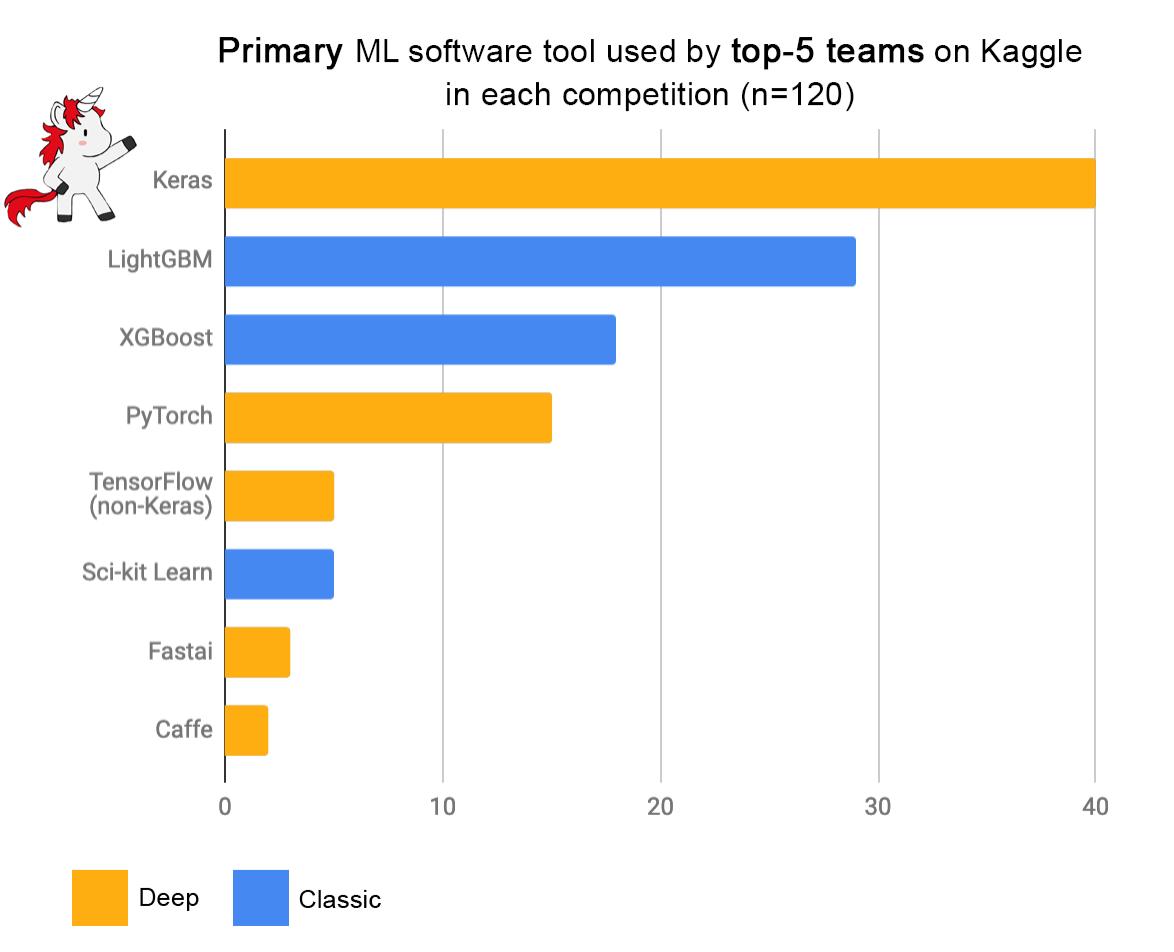
따라서 본 포스팅으로 시작되는 일련의 포스팅들에서는 Decision Tree의 기초 알고리즘부터 시작해서 XGBoost, LightBoost, CatBoost와 같은 GBDT 기반 모델들까지 정리해보고자 합니다.
목차
- 의사결정 나무 (Decision Tree) 기본 설명 (현재 글)
- 의사결정 나무 (Decision Tree) ID3 알고리즘 설명
- 의사결정 나무 (Decision Tree) C4.5 알고리즘 설명
- 의사결정 나무 (Decision Tree) CART 알고리즘 설명
- 앙상블 (Ensemble)의 기본 개념
- 배깅 앙상블 (Bagging Ensemble): Random Forest
- 부스팅 앙상블 (Boosting Ensemble) 1: AdaBoost
- 부스팅 앙상블 (Boosting Ensemble) 2-1: Gradient Boosting for Regression
- 부스팅 앙상블 (Boosting Ensemble) 2-2: Gradient Boosting for Classification
- 부스팅 앙상블 (Boosting Ensemble) 3-1: XGBoost for Regression
- 부스팅 앙상블 (Boosting Ensemble) 3-2: XGBoost for Classification
- 부스팅 앙상블 (Boosting Ensemble) 4: LightGBM
- 부스팅 앙상블 (Boosting Ensemble) 5: CatBoost
- 부스팅 앙상블 (Boosting Ensemble) 6: NGBoost
Decision Tree 의 기본 개념
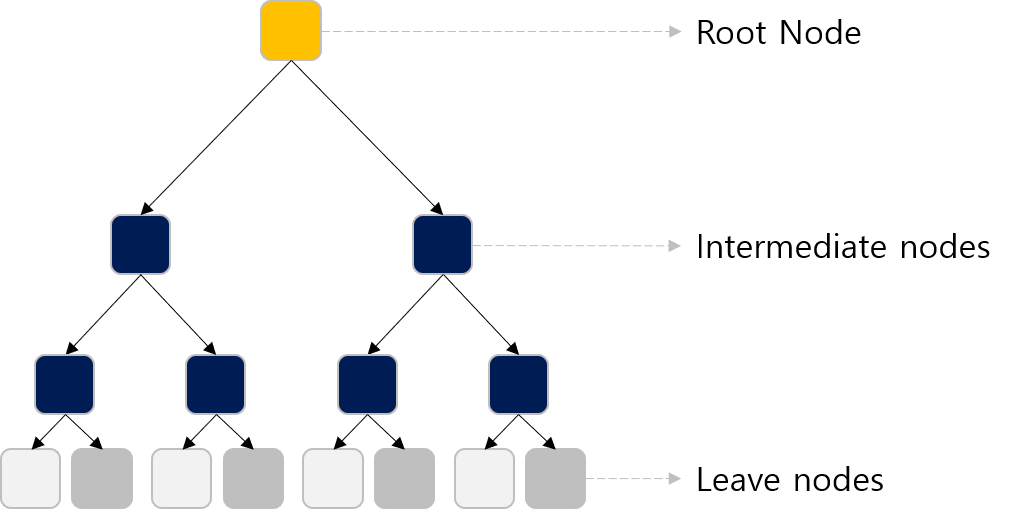
Decision Tree는 일련의 필터 과정 또는 스무고개라고 생각하면 됩니다.
아래와 같은 데이터가 있다고 생각해봅시다.
Outlook, Temperature, Humidity, Windy와 같은 기상조건들(Attributes)에 따라 운동을 할지 말지 (Play) 결정하는 모델을 만들고자 합니다.
| Outlook | Temperature | Humidity | Windy | Play |
|---|---|---|---|---|
| sunny | hot | high | FALSE | No |
| sunny | hot | high | TRUE | No |
| overcast | hot | high | FALSE | Yes |
| rain | mild | high | FALSE | Yes |
| rain | cool | normal | FALSE | Yes |
| rain | cool | normal | TRUE | No |
| overcast | cool | normal | TRUE | Yes |
| sunny | mild | high | FALSE | No |
| sunny | cool | normal | FALSE | Yes |
| rain | mild | normal | FALSE | Yes |
| sunny | mild | normal | TRUE | Yes |
| overcast | mild | high | TRUE | Yes |
| overcast | hot | normal | FALSE | Yes |
| rain | mild | high | TRUE | No |
어떤 attribute를 먼저 사용하느냐에 따라 여러 가지 Decision Tree를 만들 수 있을 겁니다. 아래와 같이 말이죠.
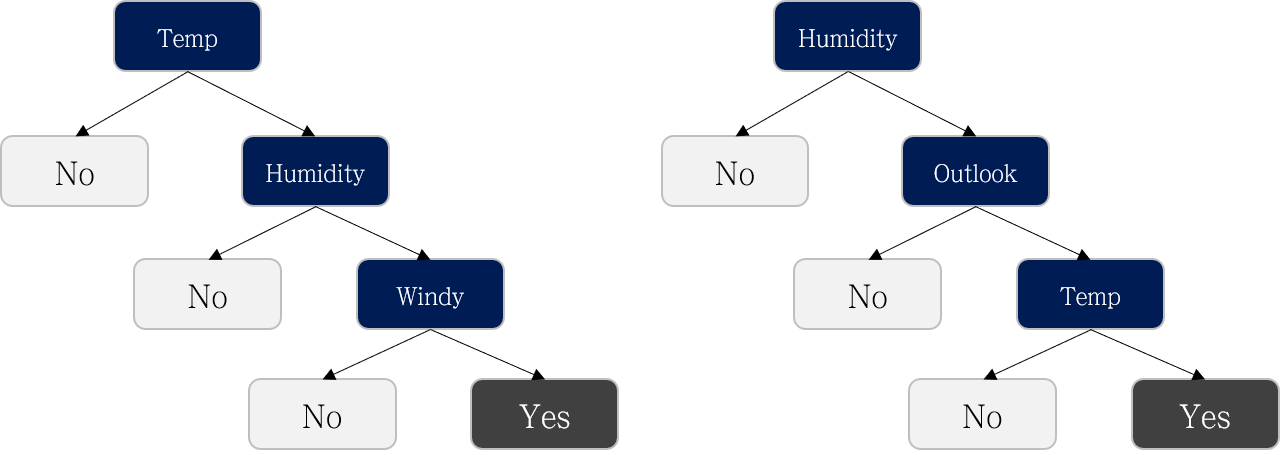 여러 Decision tree 중 더 좋은 모델을 어떻게 정할 수 있을까요?
답은 “변별력이 좋은 질문부터 먼저 정한다” 입니다.
여러 Decision tree 중 더 좋은 모델을 어떻게 정할 수 있을까요?
답은 “변별력이 좋은 질문부터 먼저 정한다” 입니다.
그렇다면, 변별력이 좋은 질문은 어떻게 정하는 것일까요?
불순도 (Impurity)
여기에서 불순도 (Impurity) 라는 개념이 등장합니다 !
 불순도는 불순물이 포함된 정도라고 생각하면 되는데, 위 그림이 잘 나타내주고 있습니다.
불순도는 불순물이 포함된 정도라고 생각하면 되는데, 위 그림이 잘 나타내주고 있습니다.
위 그림의 좌측과 우측 그림은 모든 샘플이 한 가지 라벨만을 나타내고 있기 때문에 불순도가 0인 상태입니다.
특정 지표를 기준으로 데이터셋을 나누었을 때 결과가 이와 같이 분류된다면, 이 지표는 변별력이 좋은 질문이라고 말할 수 있을 것입니다.
반면 가운데 그림의 경우, 두 가지 라벨이 섞여있기 때문에 불순도가 0보다는 큰 값을 띄게 됩니다.
마찬가지로 이 지표는 변별력이 좋지 않은 질문이라고 할 수 있습니다.
따라서 최고의 성능을 보이는 Decision Tree를 만들기 위해서는 불순도가 가장 낮은 지표를 찾아 나무를 구성해나가면 됩니다.
이 불순도를 어떤 지표를 사용하냐에 따라 알고리즘의 방향이 갈리게 되는데, 크게는 아래와 같이 엔트로피 (Entropy)와 지니 계수 (Gini index) 기반의 알고리즘으로 나눌 수 있습니다.
엔트로피 (Entropy) 기반 알고리즘
- ID3
- C4.5
- C5.0
지니 계수 (Gini index) 기반 알고리즘
- CART (Classification And Regression Tree)
이후 포스팅에서는 ID3, C4.5, CART 알고리즘에 대해서 하나씩 알아보도록 하겠습니다.
다음 글 보기: 의사결정 나무 (Decision Tree) ID3 알고리즘 설명
Leave a comment