
Classification for MEDIA (1)
이전 포스팅: Medical Image acquisition methods
이전 포스팅에서는 여러 종류의 의료영상 측정 방식에 대한 원리를 정리했습니다.
이번 포스팅에서는 Medical Image Analysis 중 Classification에 대해 정리해보도록 하겠습니다.
Difficulty of Medical image classification
의료영상 이미지는 분석하기 까다롭습니다. 몇 가지 특징 때문입니다. 예를 들어보면,
- 데이터 수집이 쉽지 않습니다. 기본적으로 환자의 개인정보라 공유하기 어렵고, 병원간 교류도 잘 되지 않습니다. 그나마 ADNI나 TCGA와 같은 곳에서 데이터를 모아 연구를 진행합니다.
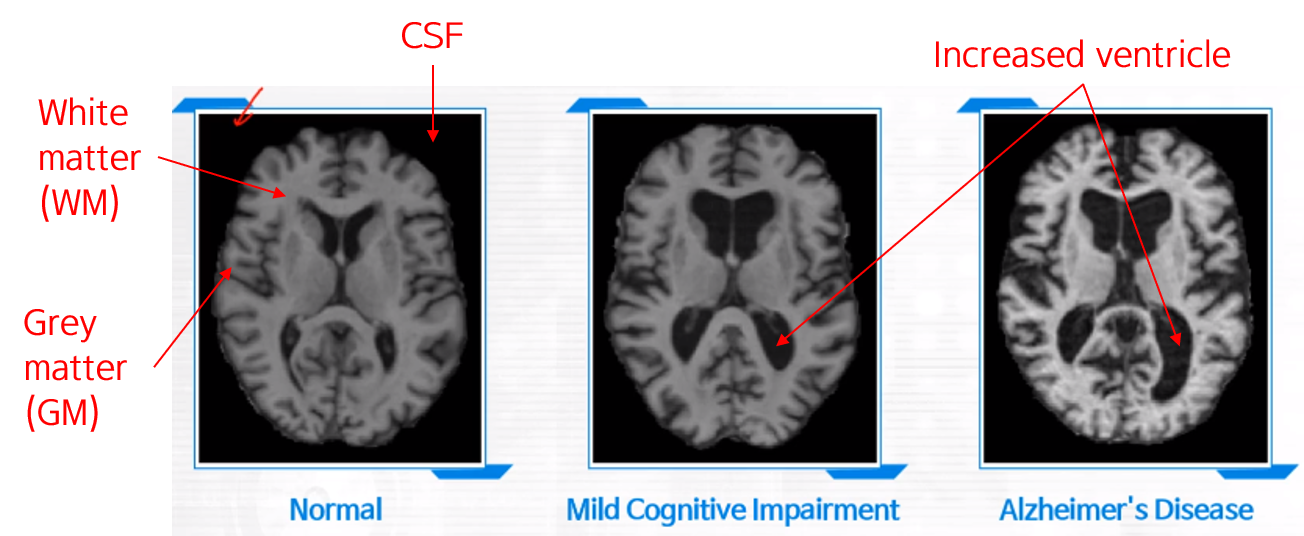
- White matter (WM)/Gray matter (GM)/Cerebrospinal fluid (CSF) 의 분포에 따라 이미지가 잘 보이지 않는 경우가 있습니다.
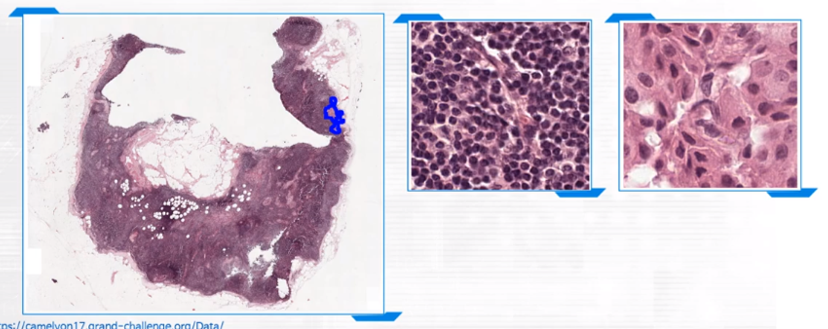
- 이미지가 큽니다 (기본 3D). 특히 pathology 데이터의 경우 이미지가 굉장히 큽니다. 그에 비해 문제가 있는 (e.g., 암세포가 있는) 영역은 매우 적은 비율을 차지합니다. 따라서 좌측의 저배율에서부터, 우측의 고배율까지 확대하면서 정상과 암세포를 구별해내야 하는데, 이 작업은 manually할 경우 상당한 노동과 시간이 소모됩니다.
-
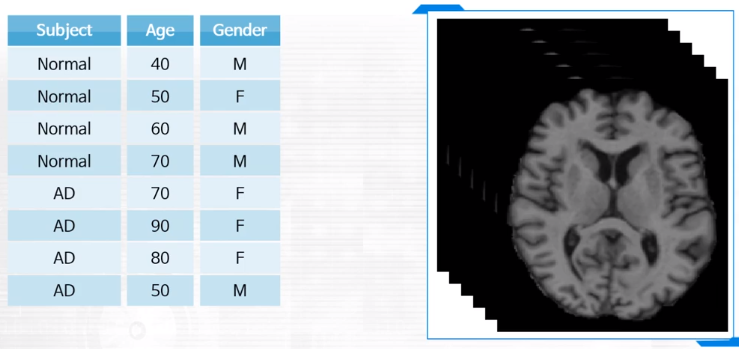
나이만 줄어도 Gray matter 영역이 줄어든다던지, Ventricle 영역이 커진다던지 하는 confounding한 변화가 존재합니다. 다시 말해, “나이”와 같은 환자의 정보가 중요한 역할을 하는 경우가 많습니다. 따라서 환자의 정보 (Demographic score)를 영상과 함께 분석할 필요가 있습니다
-
또한 상대적으로 클래스간 변화량에 큰 차이가 없습니다. 총과 칼을 구별하는 것보다 소총과 저격총을 구별하는게 좀 더 어려운 것을 떠올리면 될 것 같습니다.
-
마지막으로, 분류 시 더 보수적으로 판단해야 합니다. 즉, 일반인을 AD라고 분류하는 건 괜찮지만, AD를 일반인이라고 분류하는 것은 치명적일 수 있습니다.
그럼에도 Medical Image 분석은 계속해서 발전하고 있습니다.
Classification models

오늘 포스팅에서 다룰 Classification 알고리즘들입니다. 위 알고리즘들을 대략적으로 정리하고, Medical image classification에 사용되는 전반적인 pipeline에 대해 정리하고자 합니다.
Linear regression
가장 먼저 Linear regression입니다.
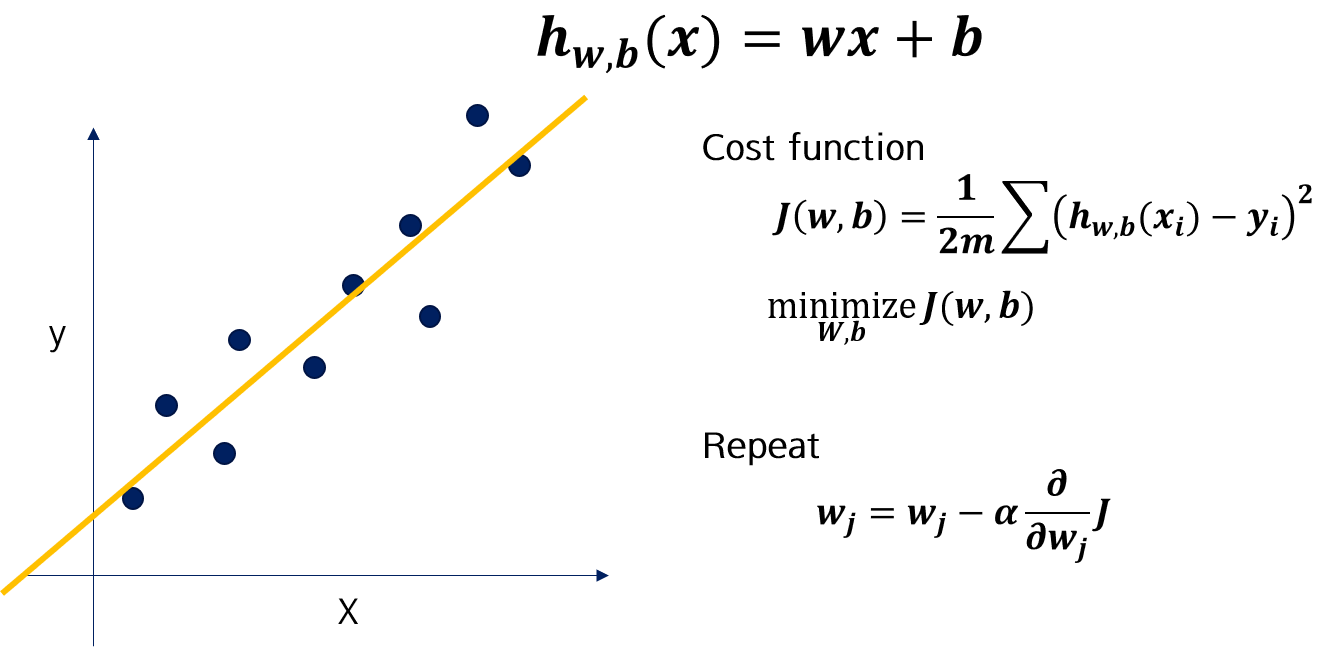
Training 데이터의 least square를 찾아 직선 모델을 적합시킵니다. 이 때 Normal equation (수식)으로 해를 찾는 것도 가능하지만, 최근에는 Gradient descent algorithm를 이용하여, Cost function이 최소화되도록 모델을 학습시킵니다. Cost function은 residual의 합으로 나타냅니다.
Gradient descent algorithm
Gradient descent algorithm을 간단히 정리하고 넘어갑니다. weight를 업데이트 할 때, Cost function의 미분값 (Gradient)와 learning rate \(\alpha\)를 곱해 기존 weight 값에서 빼줍니다.
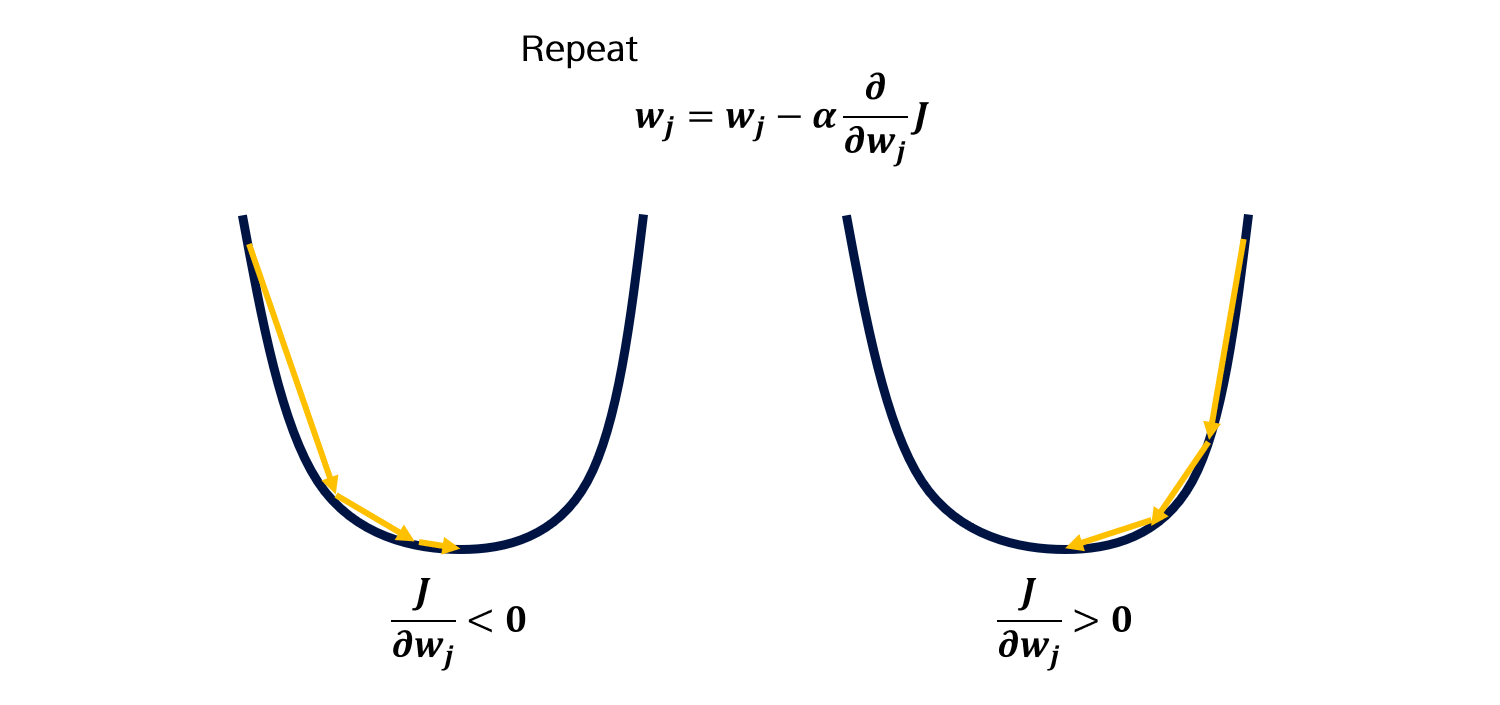
Gradient가 양수라면 weight는 감소할 것이고, Gradient가 음수라면 weight는 증가합니다.
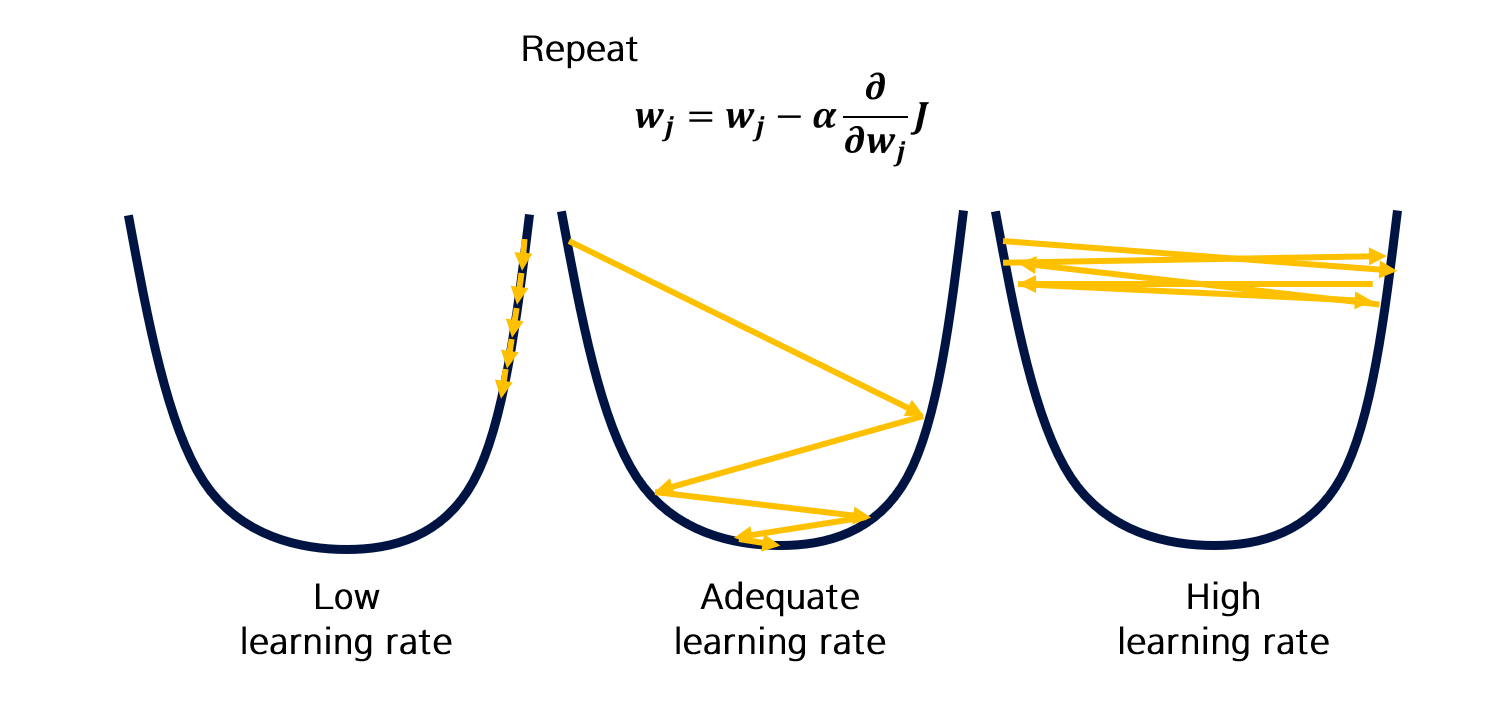
Learning rate \(\alpha\)가 너무 작다면 학습이 너무 뎌디게 진행되거나, local minima에 빠질 확률이 높습니다.
반면 \(\alpha\)가 너무 크다면 global minimum을 찾지 못할 확률이 높습니다.
따라서 적당한 \(\alpha\)를 지정해줄 필요가 있습니다.
Logistic regression
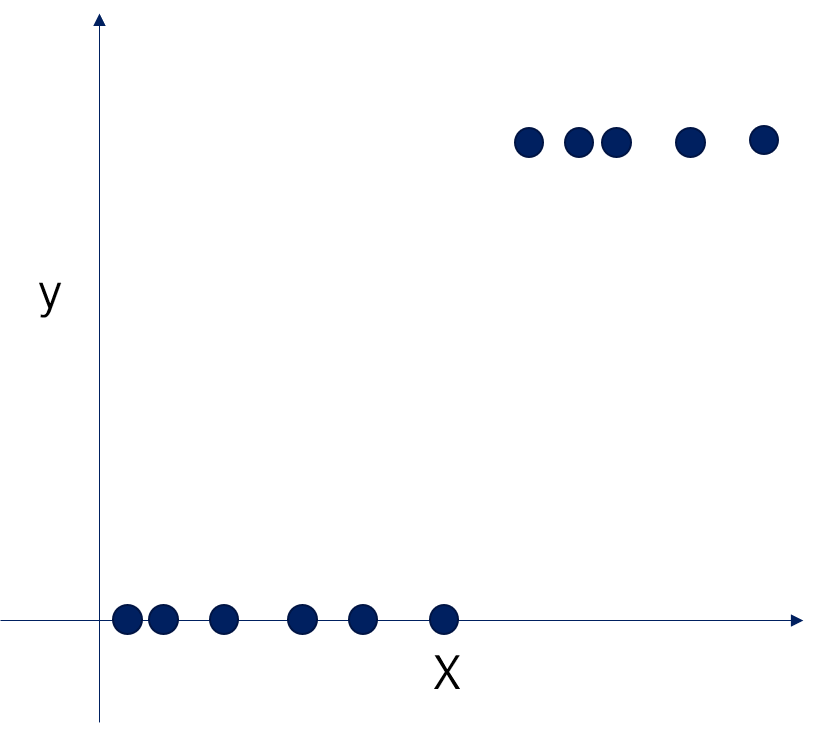
이렇게 생긴 데이터가 있다면 어떨까요? Linear regression으로는 해결하기 힘든 문제같아 보입니다. 이 데이터에 맞는 함수가 있을까요?
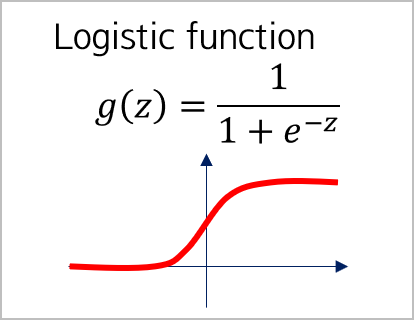
네, 있습니다. Logistic function이라고 불리우는 이 함수는 [0, 1]의 값을 갖습니다.
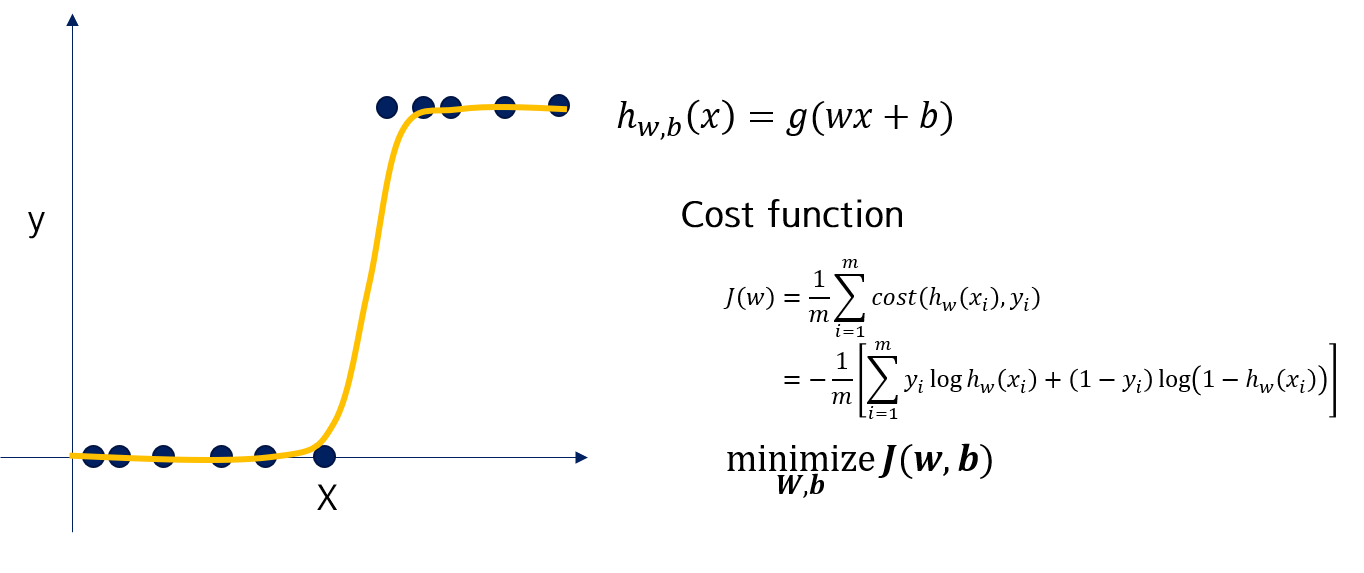
Logistic function을 Linear regression에 적용시키면, 이런 모델을 fitting할 수 있습니다.
이 때, Gradient descent를 하기에는 logistic function을 적용하여 단순 미분이 불가능하기 때문에, cross entropy와 같은 cost function을 사용합니다. 미분해서 풀면 linear regression과 같은 문제가 됩니다. (수식 생략)
Support vector machine
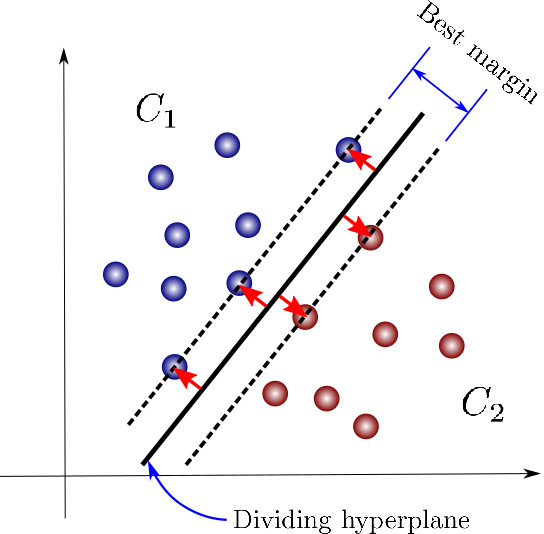
\(n\)차원 공간에서 최대의 margin을 갖는 maximum margin hyperplane를 찾아 decision boundary로 설정합니다. 이 decision boundary로 클래스를 구분짓습니다.
Support vector machine은 추후 별도 포스팅으로 정리할 예정입니다.
Random forest
Random Forest는 이전 포스팅을 참고해주세요.
의사결정 나무 (Decision tree)부터 차근차근 공부하는 것도 좋습니다.
Neural network
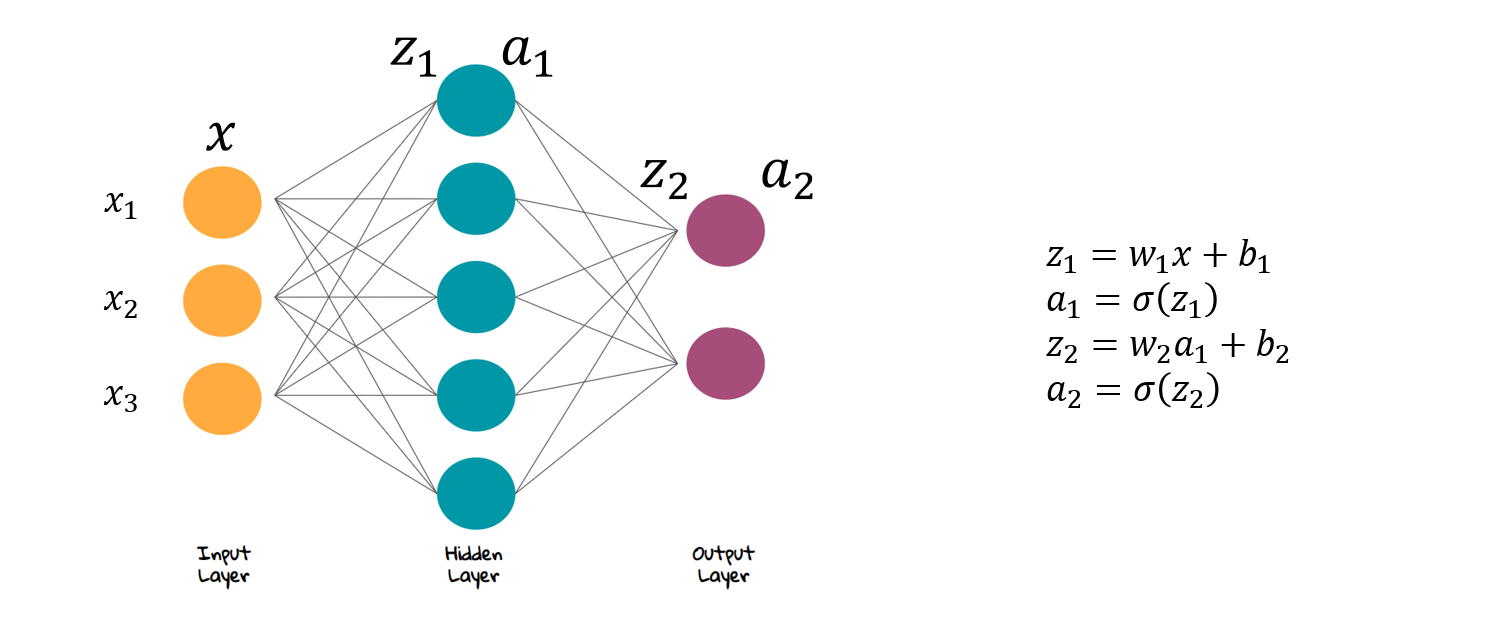
신경망 (Neural network) 구조는 Input, hidden, output layer로 구성되어있습니다. 이전 레이어의 모든 값에 가중치 \(w\)를 곱하고 bias \(b\)를 더한 뒤, activation function \(\sigma\)를 거쳐 다음 레이어로 넘깁니다 (수식 참고)
Deep neural network
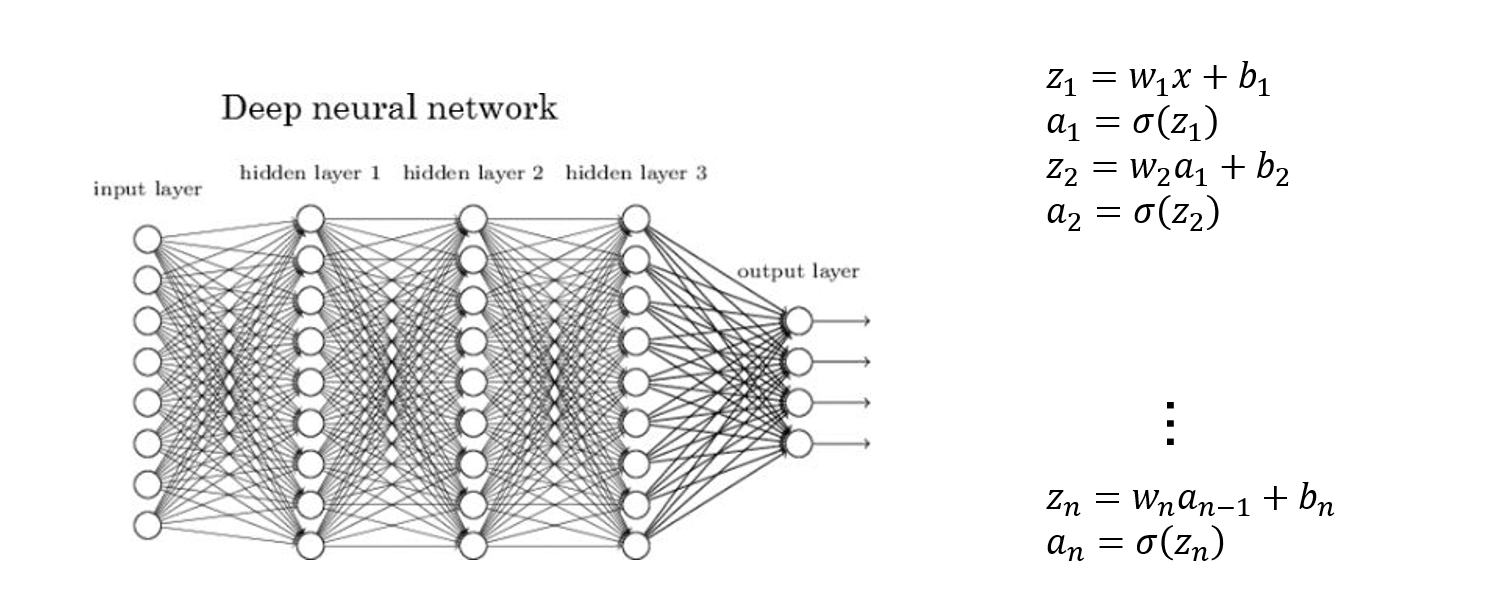
심층신경망 (Deep neural network)은 깊어진 형태의 신경망 구조를 띕니다.
다음 포스팅에서 정리합니다.
Activation functions
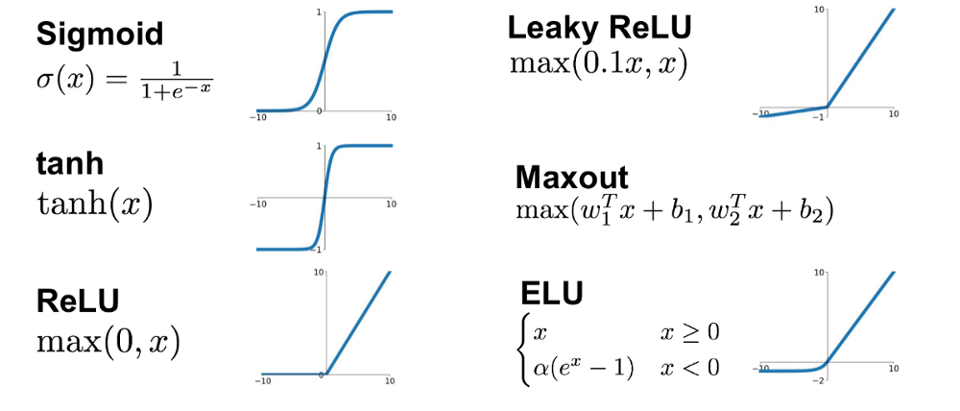
활성화 함수 (Activation function)은 위 Figure에 보이듯, 여러 종류가 있습니다. 뉴럴네트워크에 비선형성을 부여하는 핵심 함수입니다.
Procedure
이제 Medical image classification이 일어나는 과정을 정리해봅니다.
Image classification
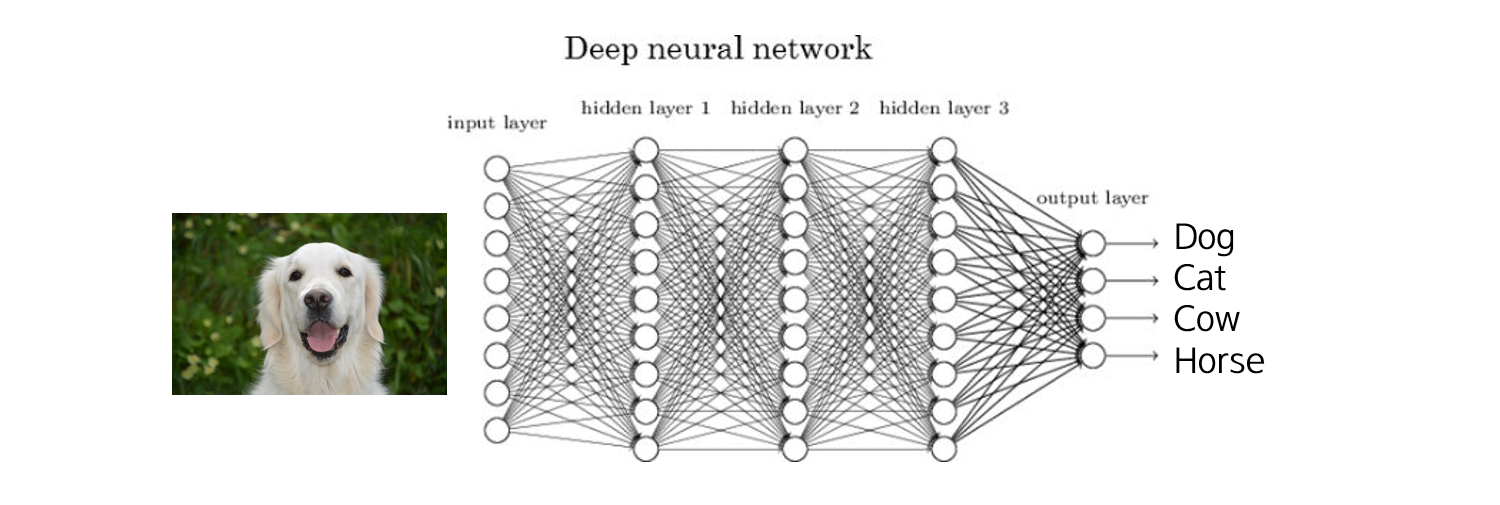
먼저 일반적인 Image classification을 보면 2D 영상을 입력으로 받아, Neural network와 같은 Classifier를 통과시켜, Dog/Cat/Cow/Horse 등 주어진 클래스에 어느 정도 해당되는지 확률값을 내놓습니다. 이 확률값이 가장 큰 클래스를 정답으로 선택하게 됩니다.
Medical image classification
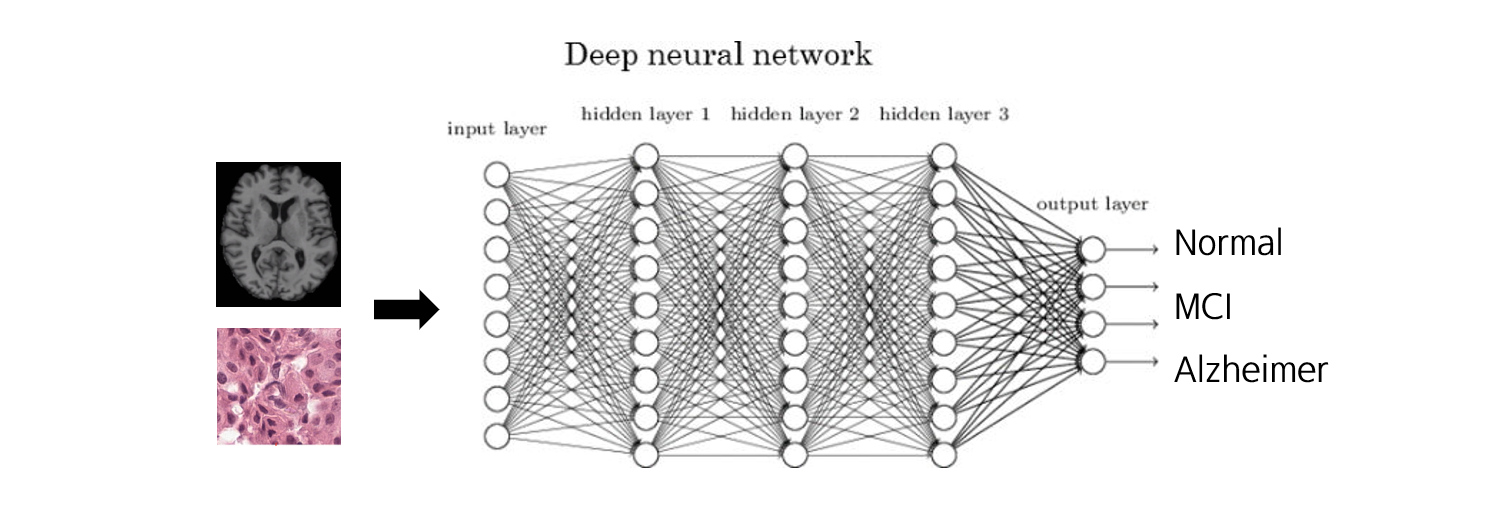
Medical image processing도 이와 비슷합니다. 다만 몇 가지 차이점이 존재합니다.
- 입력이 주로 3D 영상입니다. 즉, Classifier에 더 많은 파라미터를 필요로 합니다.
- 반면 입력 데이터의 수를 얻는 데 어려움이 있습니다. 따라서 샘플수가 적습니다.
- 위 두가지를 종합하면, 모델은 과적합될 확률이 높다는 점을 유의해야 합니다.
- 또한 MRI 이미지 같은 경우, 외곽의 검은 부분은 별 의미가 없는 부분입니다.
결과적으로, 무의미한 부분을 잘라내고 모델의 파라미터를 줄이기 위해, 의미있는 부분들만 추출하는 별도의 과정이 필요합니다.
Feature extraction
위에서 언급한 의미있는 부분들만 추출하는 과정을 Featrue extraction이라고 합니다. Parcellation라고도 부를 수 있겠네요.
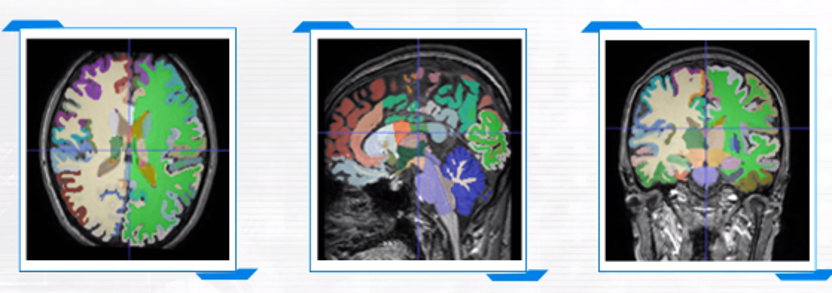
FSL이나 Freesurfer, QuPath 같은 프로그램들이 이 과정을 도와줄 수 있습니다.
Feature의 예시로는 뇌 데이터의 경우 region of interst (ROI)별 value, thickness, intensity 등이 추출될 수 있으며, Pathology 데이터의 경우 cell size, color 등이 있습니다.
Feature extraction은 연구마다 굉장히 상이하므로 간단하게만 짚고 넘어갑니다.
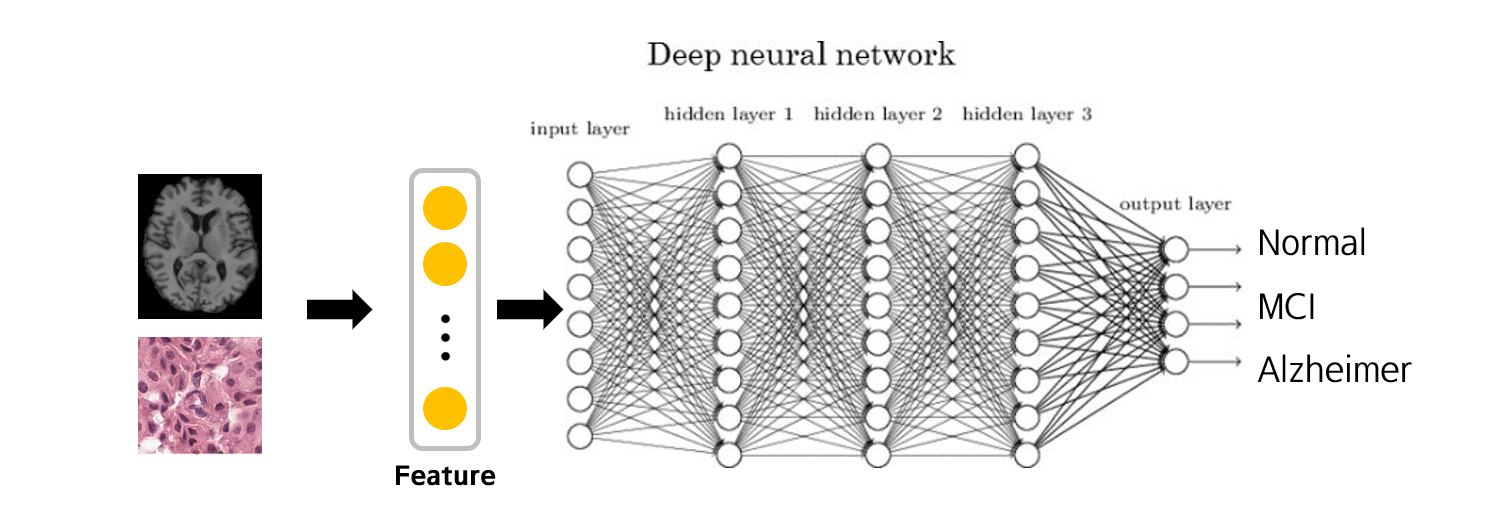
결과적으로 Feature extraction을 통해 새로운 Feature set을 얻습니다. 이를 이용하면 raw data보다는 적은 파라미터로 모델을 학습시킬 수 있게 됩니다.
Demographic score
이전 포스팅에서 언급했듯, DICOM 이미지에는 의료영상뿐 아니라 환자의 정보도 담겨있습니다. 이를 Demographic score라고 하는데, Medical image classification에는 demographic score가 활용되는 경우가 많습니다.
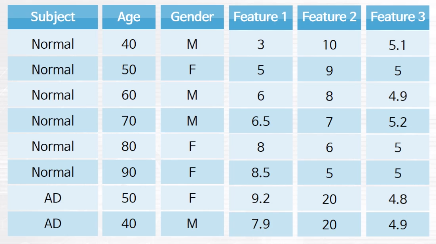
예를 들어 위와 같은 데이터가 있다고 합시다. Feature 2의 경우 환자군을 완벽히 분류해내는 좋은 feature라고 할 수 있습니다. 하지만 실제 상황에서는 이와 같은 feature를 찾는 것이 어렵고, Feature 1과 같이 애매한 feature만 있습니다.
이 feature 1을 개선하기 위해 demographic score가 사용됩니다. Feature normalization이라고하는 이 방법을 정리해봅시다.
Feature normalizer
Feature normalization을 위해 demographic score들을 X로, Feature를 y로 두고 Linear regression을 시행합니다.
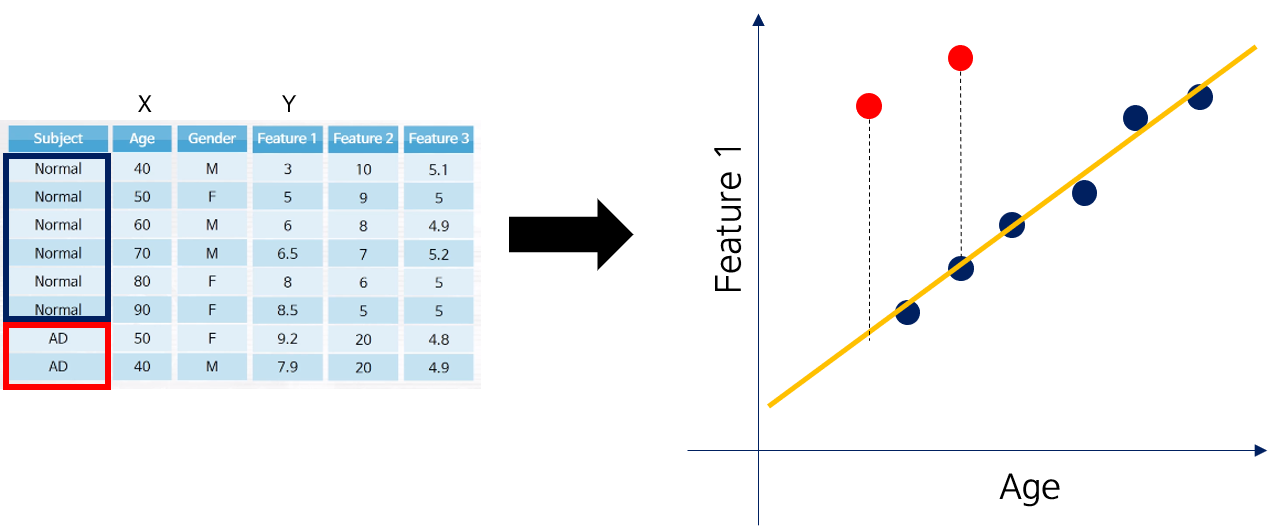
예를 들어 \(Feature\; 1=W\times Age+b\)와 같은 수식으로 Linear regression을 시행합니다. (실제로는 여러 종류의 demographic score를 이용해서 feature 값을 추정하지만, 시각화의 편의를 위해 Age 변수만 사용했습니다)
이 때, 모든 데이터를 다 활용하는게 아니라, Normal 그룹의 데이터로만 Linear regression을 적합시킵니다. 이후 각 샘플에 대해 예측값 - 실제값의 차이인 residual을 계산합니다.
Normal 그룹에 적합된 linear model이기 때문에, 상대적으로 AD (환자군) 그룹은 큰 residual을 갖게 되어 feature의 변별력이 개선되는 효과가 있습니다.
📌
NOTE: 각 feature에 대해 이 과정을 수행하기 때문에, 전체적인 feature 수는 변화가 없습니다.
Overall procedure
결과적으로 medical image classification 과정을 그림으로 나타내면 아래와 같습니다.
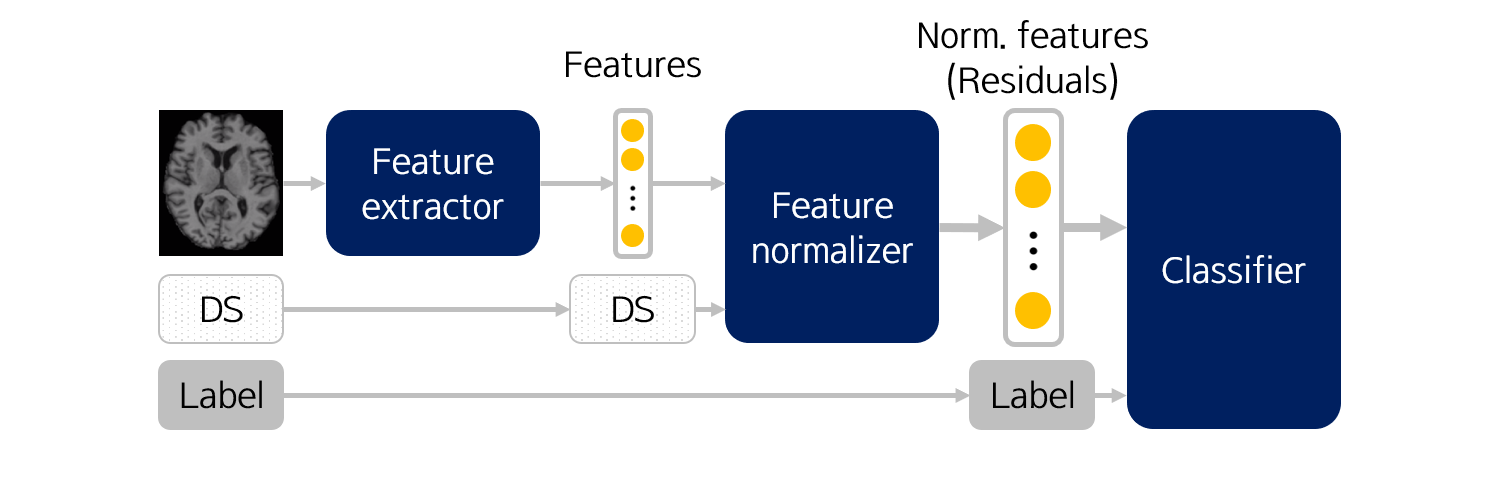
Training 시,
- Raw 이미지로부터 Feature extractor를 학습시키고, training data에 대한 feature를 추출합니다.
- Demographic score를 활용하여 Feature noramlizer를 학습시키고, training data에 대한 normalized feature를 추출합니다.
- Normalized feature와 label을 이용하여 classifier를 학습시킵니다.
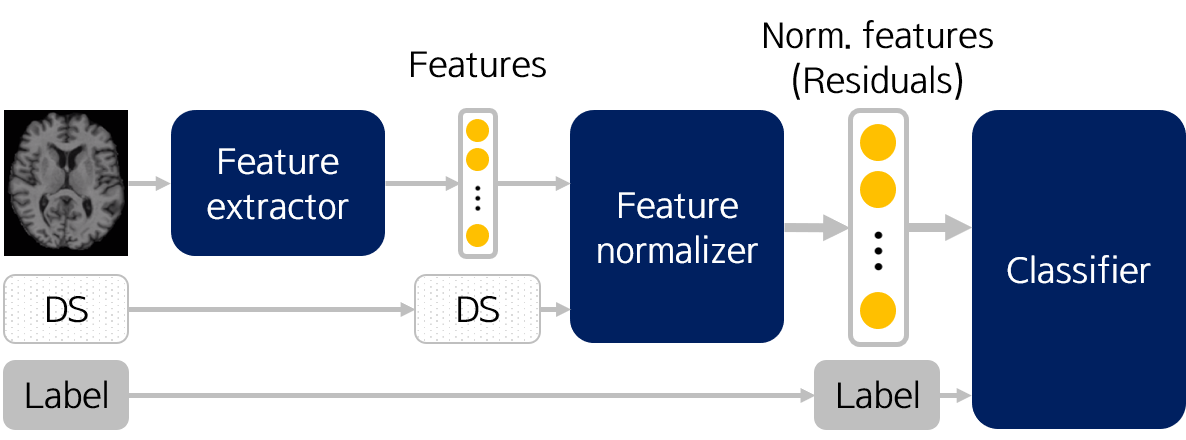
Test 시,
- 학습된 Feature extractor로부터 test data에 대한 feature를 추출합니다.
- 학습된 Feature normalizer로부터 test data에 대한 feature를 normalize합니다.
- 학습된 classifier로부터 test data의 normalized feature에 대한 label을 얻습니다.
간단하군요 😎 !
위 파이프라인은 어디까지나 하나의 예시입니다. 예시에서는 demographic score를 feature normalization에 사용했지만, 또 다른 예시에서는 feature 자체로 사용할 수도 있습니다.
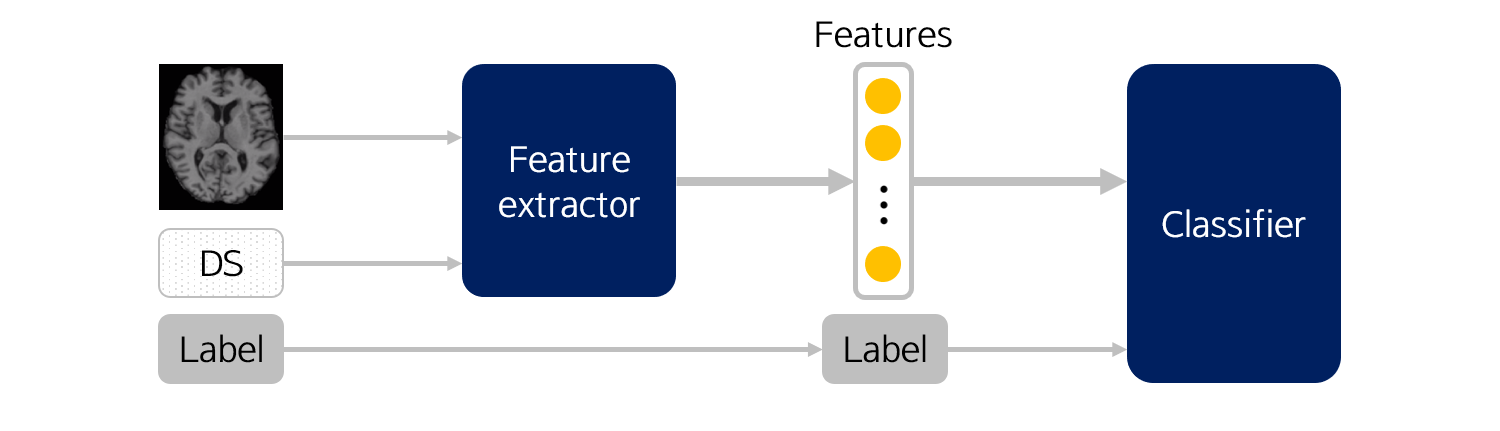
이렇게 말이죠. 다만, 이 때는 demographic score의 전 분포에 대해 충분한 수의 샘플 수가 확보되어야 합니다.
다음 포스팅에서는 deep neural network 알고리즘을 조금 더 정리하고자 합니다.
Leave a comment