
Classification for MEDIA (2) Deep neural network
이전 포스팅: Classification for MEDIA (1)
이전 포스팅에서는 Medical Image Analysis 에 사용되는 Classification 방법들을 간단하게 정리해보았습니다.
이번 포스팅에서는 그 중 Deep neural network (DNN)에 대해 좀 더 정리해보도록 하겠습니다.
Deep neural network
Deep neural network (심층신경망)을 이해하기 앞서, 앞서 정리한 다른 모델들을 다시 한번 살펴봅시다. 쭉 이어집니다 !
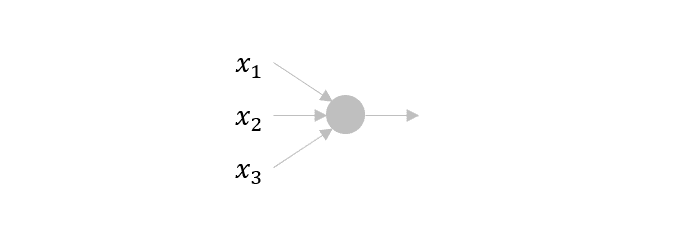
Logistic regression \(y=WX+b\)를 그림으로 표현해보면 위와 같습니다. 입력값에 가중치를 곱해 모두 더한 형태이지요 (bias는 그림에서 생략합니다).
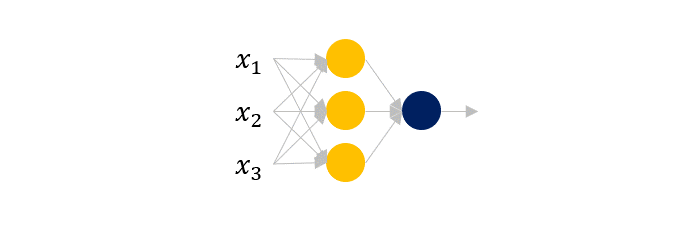
그리고 Neural netowrk (신경망) 모델은 이렇게 표현됩니다.
\[ y=\sigma(\sum_i w_ix_i+b) \]
위와 같은 특징을 갖는 인공 뉴런이 여러 층 쌓여있는 형태가 됩니다.
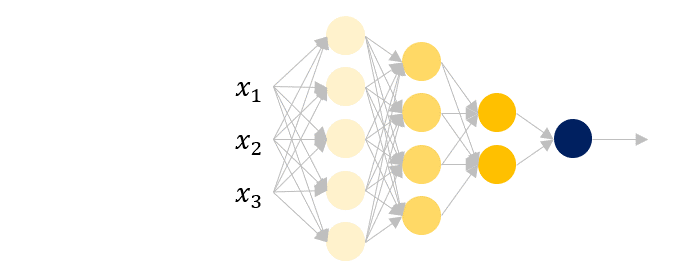
Depp neural network (심층신경망)은 말 그대로 깊이가 깊게 (여러 층의 레이어) 구성된 신경망 모델입니다. 이 그림에서 입력은 벡터 형태로 되어있습니다. 하지만 의료영상에서는 입력이 벡터가 아닌, 이미지 형태로 되어 있는 경우가 많습니다.
이럴 때는 어떻게 될까요?
Deep neural netwowk with image
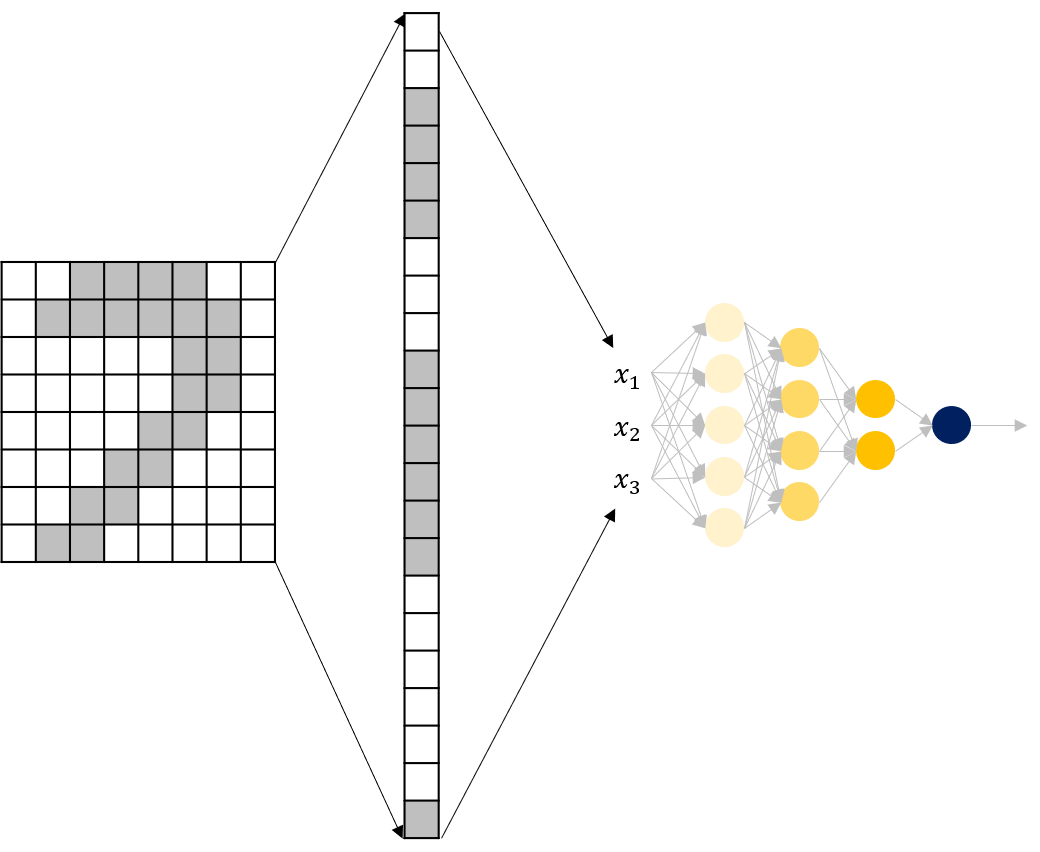
가장 간단한 방법은 이미지를 벡터화시키는 것입니다. 위 그림과 같이 이미지를 한 줄로 쭉 펴서 표현한다면, 입력 노드 수가 많은 DNN 모델로 구성할 수 있습니다.
또 다른 방법은 Convolution을 이용하는 것인데, 이는 다음 포스팅에서 다룰 예정입니다.
Property of deep layers
DNN에서 각 레이어가 하는 일은 무엇일까요?
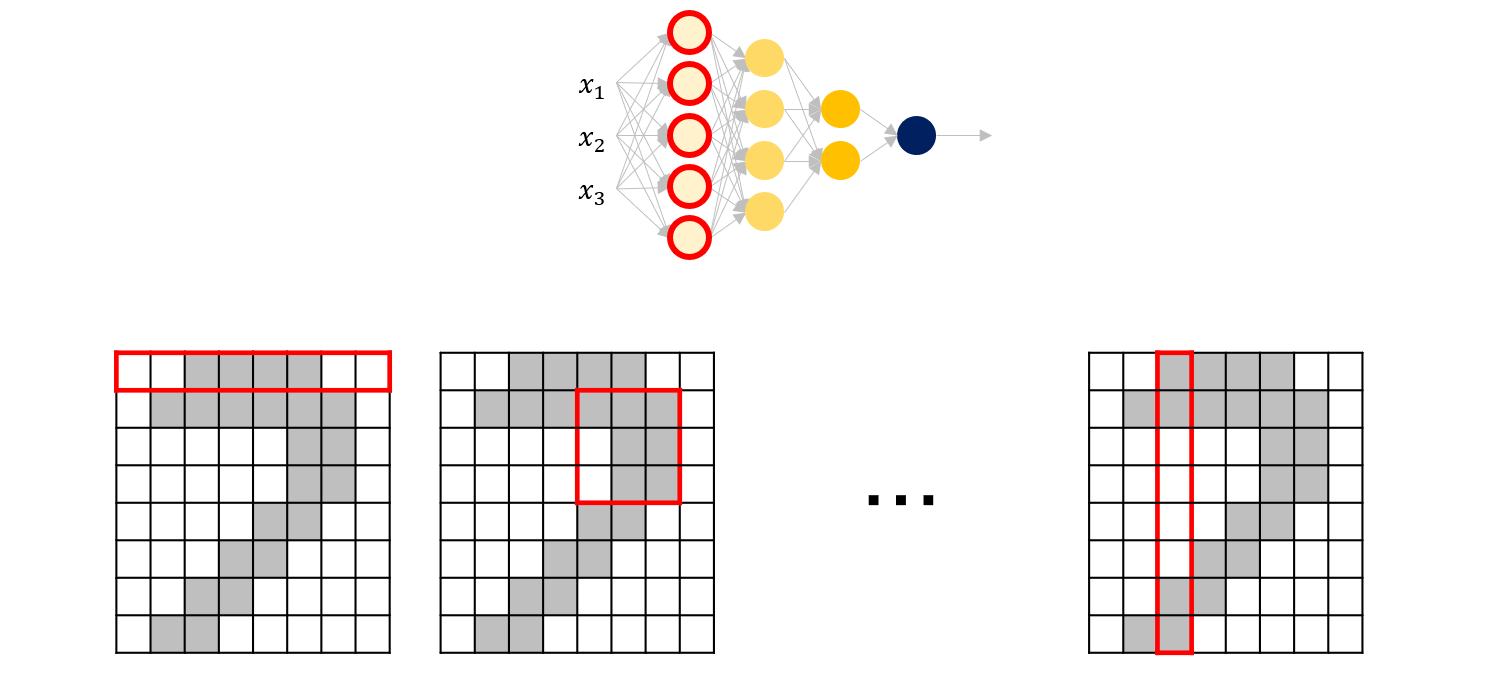
일반적으로 DNN 구조는 뒤쪽 레이어로 갈 수록 노드 수가 점차 감소하도록 디자인합니다.
따라서 앞단의 레이어들은 입력값이 많습니다. 이는 각자 맡은 영역이 잘게 분포되어 있다고 볼 수 있습니다.
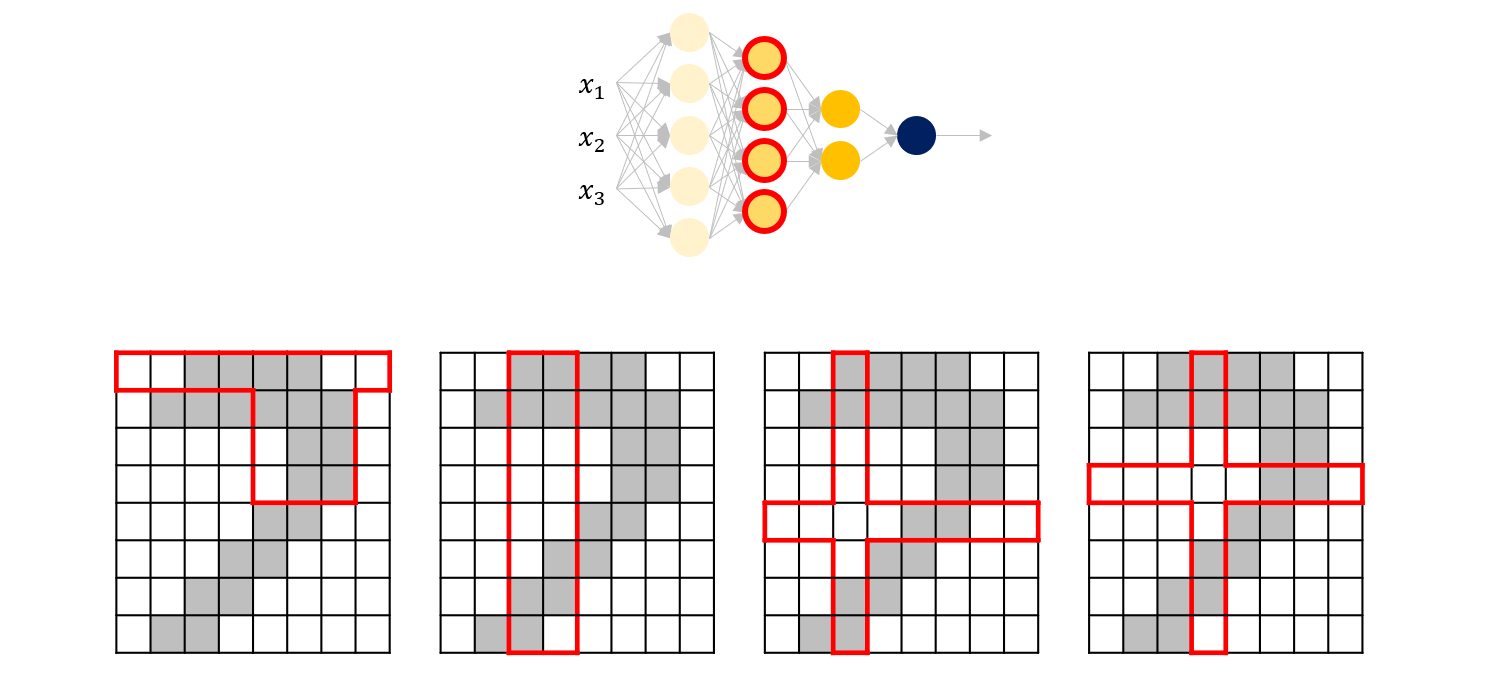
다음 레이어는 앞의 레이어들이 담당하는 영역의 데이터를 모두 받아옵니다. 따라서 각 노드가 담당하는 영역이 조금씩 커집니다.
위와 같이 뒤로 갈수록 영역이 점차 커지게 됩니다.
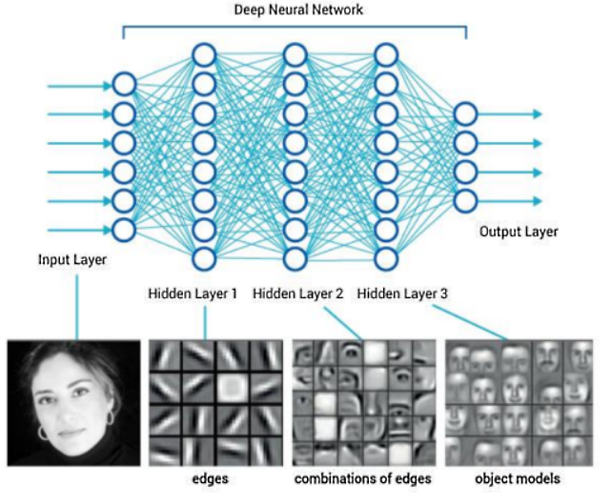
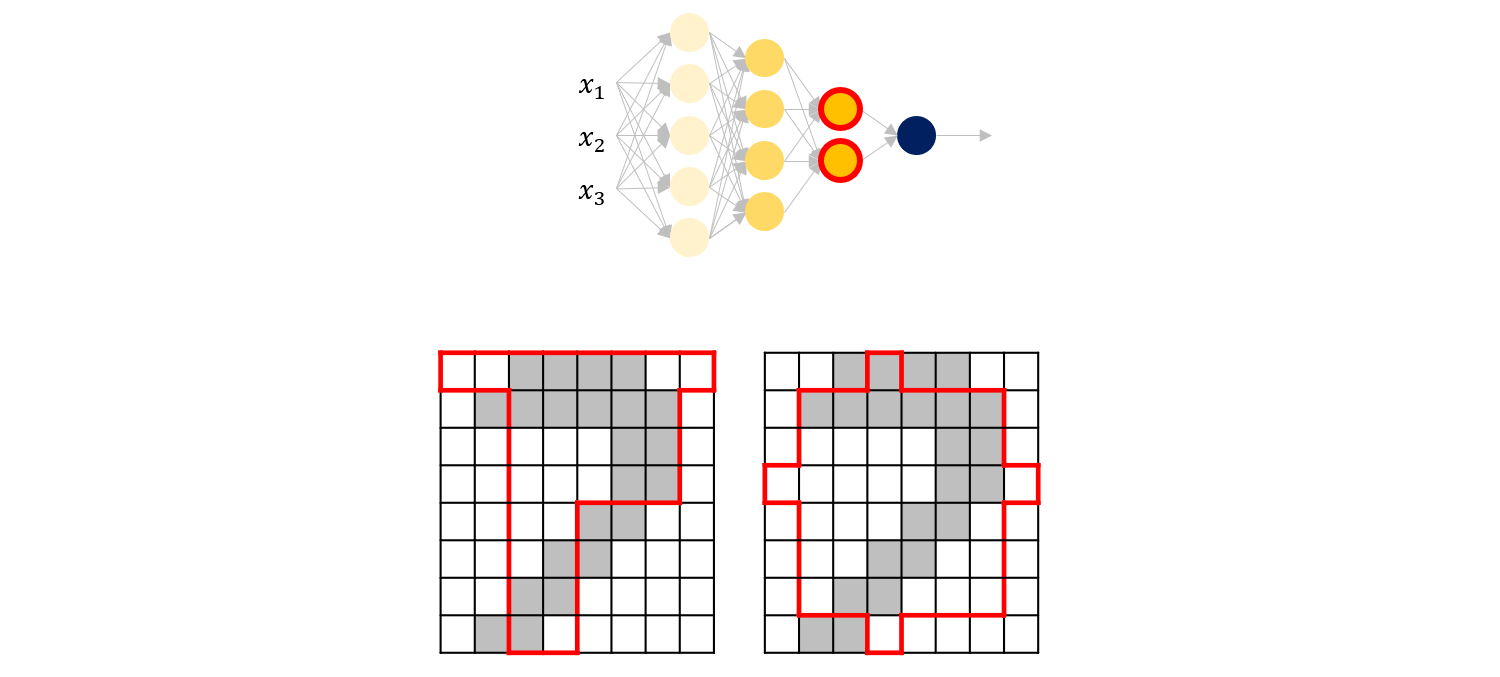
즉, 앞단의 레이어는 이미지의 세부적인 포인트 (edge)를 extraction해내며, 뒤로 갈수록 각 레이어에서 추출하는 feature가 점차 object의 형태를 띄게 됩니다.
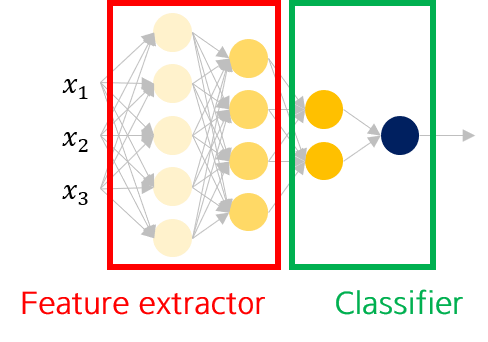
즉, DNN은 Feature extractor와 Classifier가 합쳐진 end-to-end learning으로 볼 수 있습니다.
Importance of data size
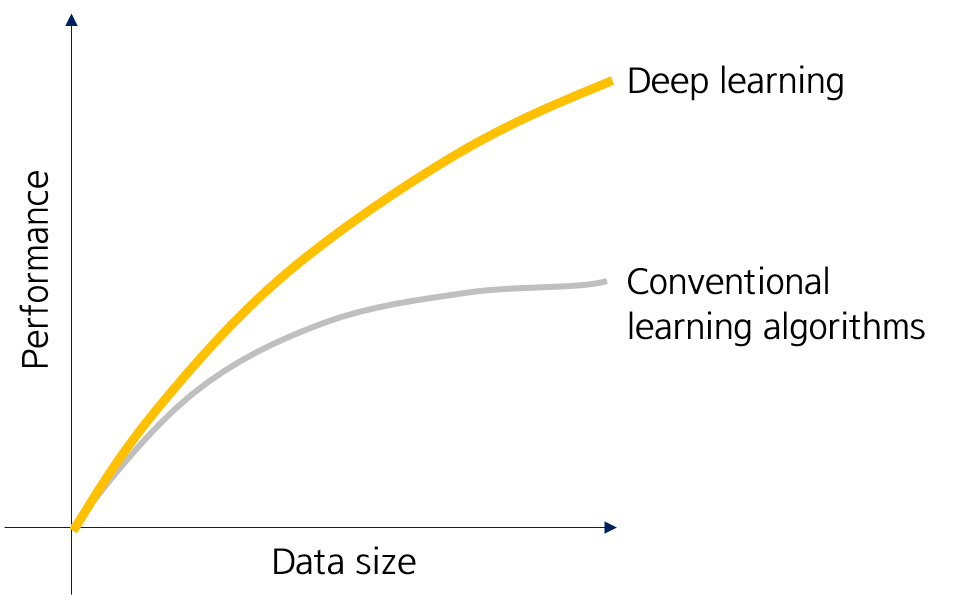
하지만 익히 알고 있듯, 딥러닝 모델은 데이터 사이즈가 충분히 많을 때 더 높은 성능을 냅니다. 특히 이미지 형태의 데이터를 DNN에 사용하게 되면, 이미지 크기, 레이어 수, 노드 수에따라 모델 학습에 필요한 weight가 엄청나게 증가한다는 단점이 존재합니다.
📌
NOTE: 의료영상의 도메인 특성상, 데이터 수를 충분히 확보하기가 어렵기 때문에, conventional한 방법이 더 좋은 성능을 내는 경우도 많다고 합니다.
Deep neural network의 기본적인 구조와 레이어 위치에 따른 특징을 정리해보았습니다. 본문에 언급한 바와 같이, 이미지 형태의 데이터를 DNN에 사용하게 되면, 학습이 필요한 파라미터 수가 너무 많아집니다. 이를 해결하기 위해 Convolution을 적용한 Convolutional neural network가 많이 사용되고 있습니다.
다음 포스팅에서는 Convolutional neural network (CNN) 모델의 기초에 대해 정리해봅니다.
다음 포스팅: Classification for MEDIA (3) Convolutional neural network
Leave a comment