
Classification for MEDIA (4) Advanced CNN models
이전 포스팅: Classification for MEDIA (3) Convolutional neural network
이전 포스팅에서는 이미지 데이터에 많이 활용되는 Convolutional neural network (CNN)의 기초에 대해 정리해보았습니다.
이번 포스팅에서는 주요 CNN 모델들에 대해 정리해보고자 합니다. 굉장히 빠르게 연구가 진행되는 분야인만큼, 몇 년 되지 않았지만 고전 모델 (…)로 불리는 모델들이라 곳곳에 더 좋은 정보가 이미 많아 (예: 라온피플 블로그, 본 포스팅에서는 최대한 핵심만 정리하도록 합니다.
본 포스팅에서 다룰 CNN 구조는 아래와 같습니다.
- LeNet-5 (1998)
- AlexNet (2012)
- Inception (2014)
- VGGNet (2014)
- ResNet (2015)
- DenseNet (2017)
LeNet-5 (1998)
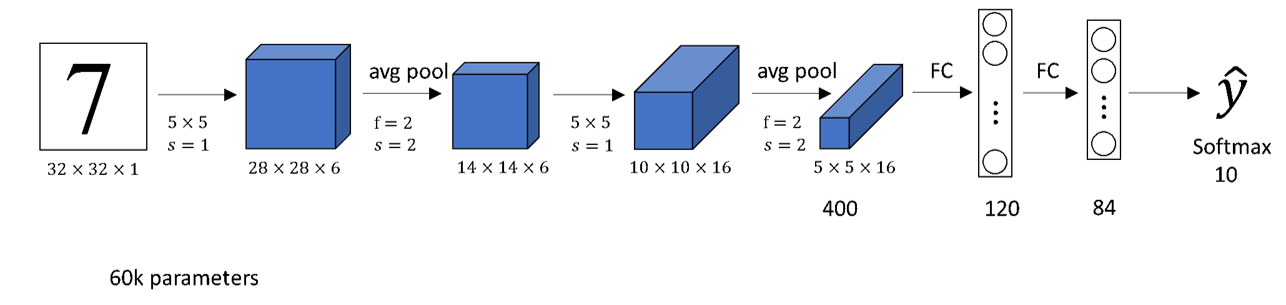
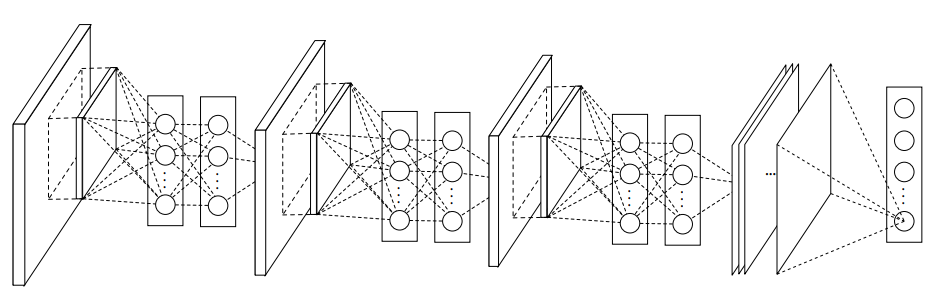
CNN의 기본적인 구조를 띄는 LeNet-5입니다. 뒤로 갈수록 이미지의 사이즈가 줄어드는 대신 채널 수 (depth)가 늘어나는 구조를 띄고 있습니다.
AlexNet (2012)

2012년 ImageNet이미지를 기반으로 한 분류 대회인 ImageNet Large-Scale Visual Recognition Challenge 2012에서 캐나다 토론토 대학이 우승합니다. Alex Khrizevsky, Ilya Sutskever, Geoffrey Hinton으로 구성된 이 팀의 메인 저자인 Alex Khrizevsky의 이름을 딴 AlexNet은 압도적인 성능으로 1위를 하게 됩니다.
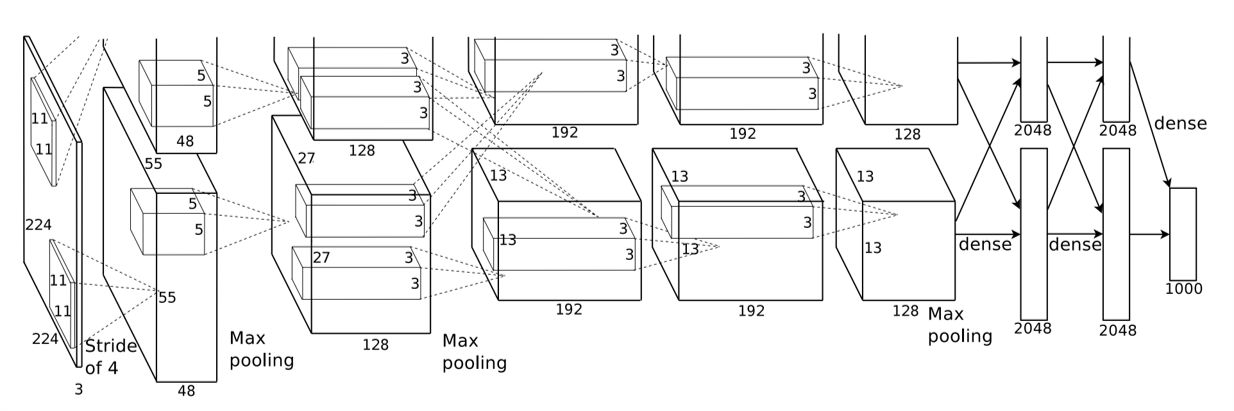
AlexNet의 구조인데, 이미지가 상당히 어지럽습니다. 크게 보면 위와 아래의 모델이 있는데, 이는 2개의 GPU를 사용 병렬구조임을 나타냅니다. 즉, GPU 병렬구조만 제외하면 앞서 살펴본 LeNet-5과 비슷합니다.
이전에 사용해오던 Sigmoid 나 tanh activation function은 학습 속도가 느리다는 치명적인 단점이 있었습니다. Alex-Net에서는 이에 대한 대체재로 ReLU 함수를 사용했고, 지금까지 ReLU는 대표적인 Nonlinear activation function으로 사용되어오고 있습니다.
Inception, GoogLeNet (2014)
Szegedy et al.,에 의해 2014년 Going Deeper with Convolutions라는 논문으로 “Inception”이라는 개념이 제안됩니다. 2010년 개봉한 영화 인셉션의 그 인셉션 맞습니다.
그리고 그 해 ImageNet Large-Scale Visual Recognition Challenge 2014에서 Inception을 적용한 GoogLeNet이 좋은 성적을 거두면서 유명해집니다.
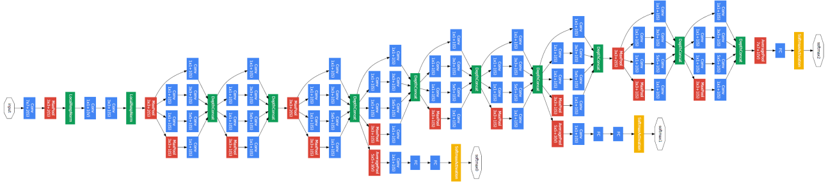
GoogLeNet은 이전의 모델 (~10 layers)에 비해 깊은 네트워크 (22 layers)를 보여줍니다. 일반적으로 네트워크가 깊어질 수록 성능이 좋아지는 것은 잘 알려져 있습니다. 다만 이 경우, 학습해야 하는 파라미터가 늘어나기 때문에 느린 학습 속도 및 Overfitting의 가능성이라는 문제점이 존재합니다.
또한 이런 모델을 설계할 때, 모델의 필터 사이즈나 하이퍼파라미터를 설정하는 데 있어 여러 문제점이 있을 것입니다.
Inception (GoogLeNet)에서는 이 문제를 Inception module을 활용하여 어느 정도 해결하였습니다. 실제로 Inception 모델은 AlexNet보다 모델의 깊이가 깊음에도 파라미터의 수나 연산량을 비교하면 AlexNet보다 적습니다.
Network In Network (NIN)
Inception Module을 정리하기에 앞서, Network in Network라는 구조에 대해 이해할 필요가 있습니다.
싱가포르 국립대학의 Min Lin은 2013년 Network In Network라는 논문을 발표합니다.
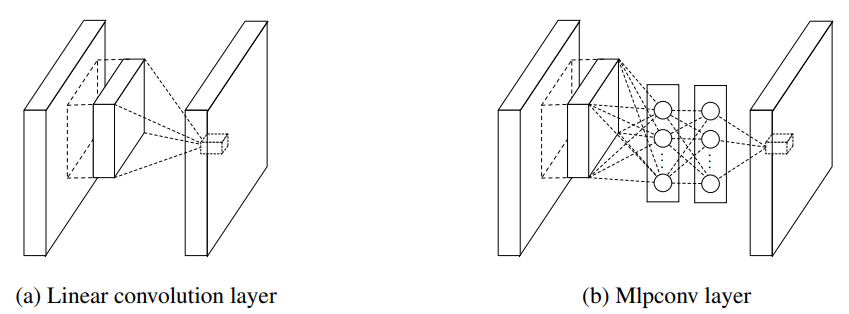
일반적인 CNN의 Convolutional layer는 local한 receptive field 내에서 feature를 추출해내는 능력은 우수한 반면, filter의 연산이 linear하게 일어나기 때문에 non-linear feature를 추출하는데는 어려움이 있을 것이라고 생각했습니다.
이를 해결하기 위해서는 filter의 개수를 늘려 연산량을 늘리는 방법밖에 없었는데, NIN에서는 우측의 그림과 같이 Convolution 대신 MLP를 이용하여 feature를 추출하는 방법을 사용했습니다.
네트워크 안에 다른 네트워크 (MLP)를 쌓아올린 형태 때문에 Network In Network 라는 이름이 붙었습니다.
Inception module
Inception에서는 Network In Network 개념을 Inception module을 여러 층 쌓는 형식으로 사용했습니다.
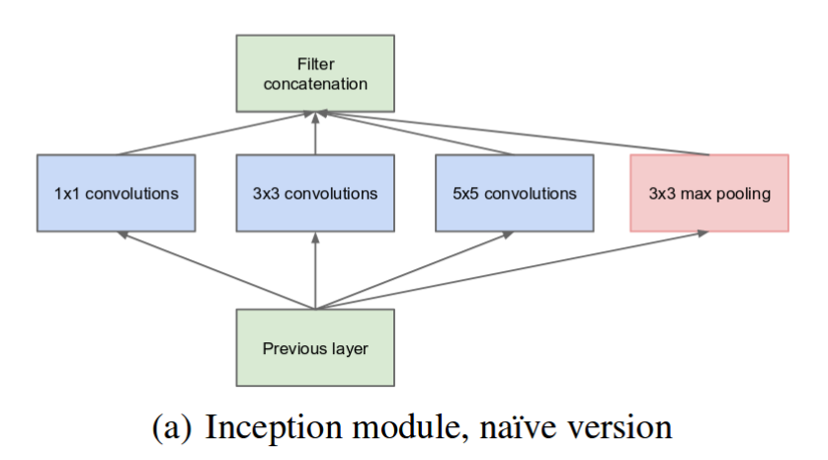
초기 Inception module에서는 한 층의 레이어에서 여러 필터 사이즈를 사용한 뒤, 출력 이미지만 맞추어 결과를 concatenate해서 사용하는 naive inception module을 구상하였습니다.
다만 이 경우, 모델의 후반부로 갈 수록 채널 개수 (depth)가 너무 깊어져서 연산량이 과도하게 증가하는 문제점이 발생했습니다.
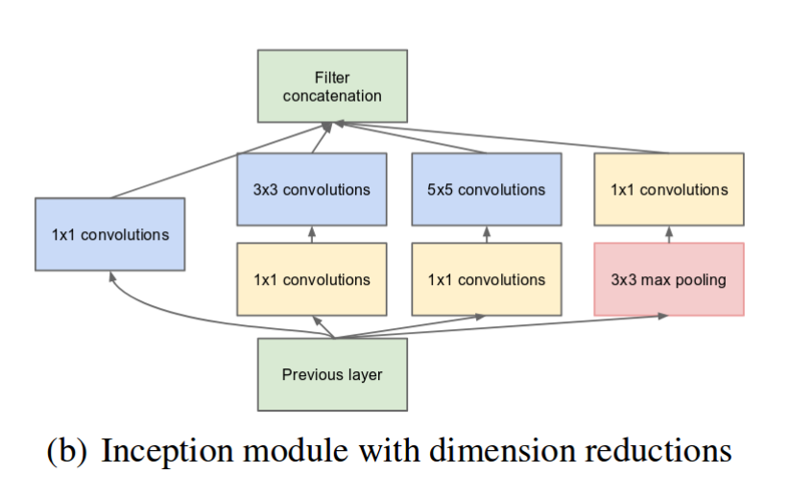
따라서 dimension reduction을 적용시킨 inception module을 적용했는데, dimension reduction은 1x1 filter를 이용하여 진행했습니다.
naive inception module과 비교했을 때, 3x3, 5x5 convolution filter와 3x3 max pooling layer 전후에 1x1 filter가 적용된 것을 확인할 수 있습니다.
1x1 convolution
1x1 filter는 bottleneck layer로써 depth를 감소시켜 모델의 연산량을 줄여주는 역할을 합니다. 1x1이 아니라 더 큰 filter size를 써도 되기는 하지만, 연산량의 최소화를 위해 1x1 filter를 사용합니다.
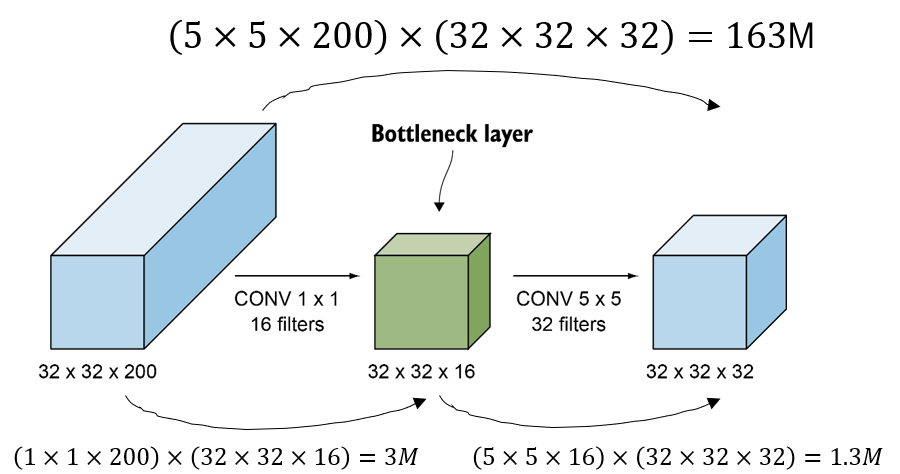
위 예시에서 1x1 filter를 이용해 depth를 200에서 32로 바로 줄이는 것이 아니라, 200에서 16을 거쳐 32로 줄이는 것을 확인할 수 있습니다.
이 경우 모델의 연산량을 비교해보면, 163 millions에서 4.3 millons 로 엄청나게 감소되는 것을 확인할 수 있습니다.
1x1 convolution은 연산량의 감소뿐 아니라 한 층의 nonlinear activation function을 추가함으로써 모델의 비선형성을 더 증가시키는 역할도 수행합니다.
다시 Inception net의 전체적인 그림을 보면, Inception module이 반복해서 이어져있는 형태인 것을 확인할 수 있습니다. 9개의 Inception module을 통해 전체적인 연산량을 줄이면서 더 깊은 모델을 쌓아 좋은 성능을 낼 수 있었습니다.
Auxiliary classifier
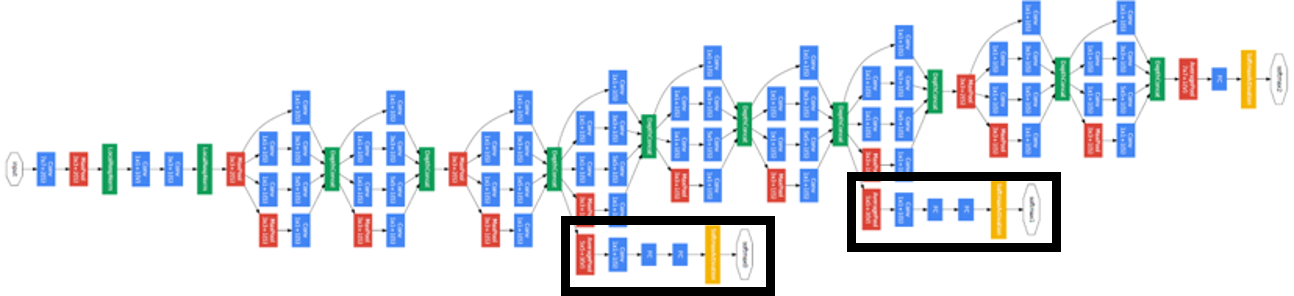
그런데 위 그림에서 노란색 블락을 볼 수 있습니다. 이전 모델에서는 보지 못했던 특이한 구조인데, Auxiliary classifier라는 구조입니다.
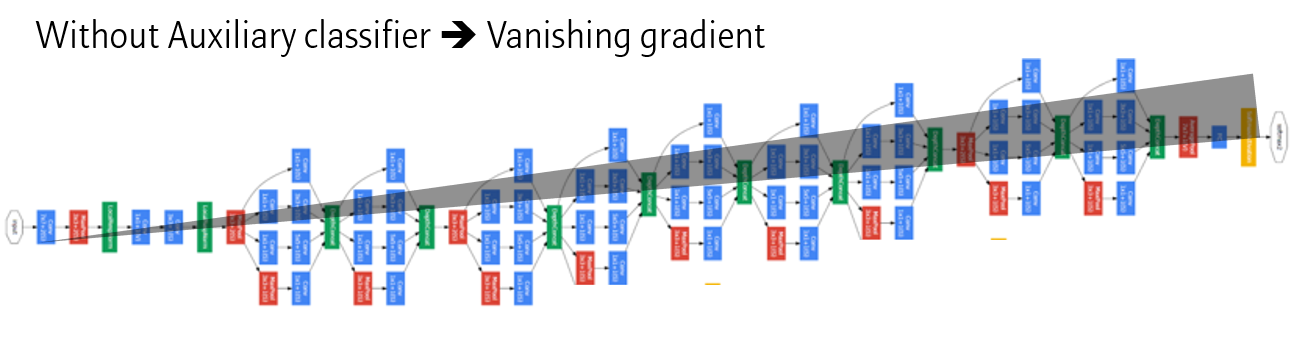
망이 깊어지면서, Gradient을 Backpropagation 할 때, 점차 미분값이 0으로 수렴하는 vanishing gradient 문제가 발생합니다.
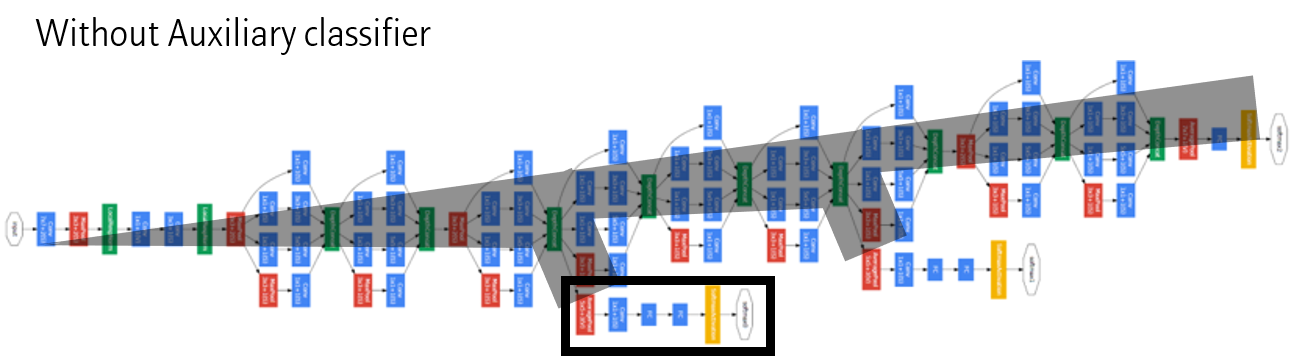
학습을 도와주는 역할을 하는 Auxiliary classifier를 모델 중간중간에 배치하면 감소하던 Gradient에 추가적인 Gradient를 더해주는 효과를 얻게됩니다. 따라서 Vasnishing gradient 문제를 다소 해결할 수 있게됩니다.
Auxiliary classifier는 학습이 끝나면 제거합니다. 즉 Test 시에는 사용하지 않습니다.
VGGNet (2014)
GoogLeNet이 우승했던 ImageNet Large-Scale Visual Recognition Challenge 2014에서 2위는 옥스포드 대학교의 VGGNet이었습니다.
비록 2위를 하긴 했지만, GoogLeNet에 비해 구조적으로 단순하고 변형이 용이하기 때문에, 지금까지도 많이 사용되는 네트워크입니다.
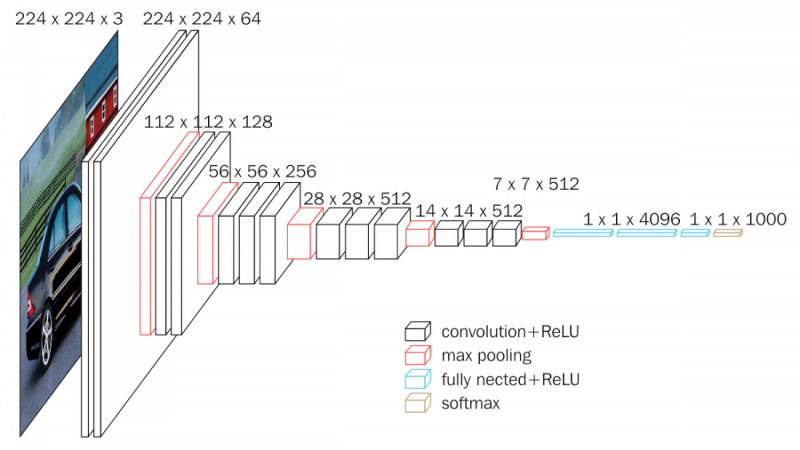
VGGNet의 구조는 간단합니다. Filter size가 큰 (e.g., 5x5, 7x7) 필터 1개를 사용하는 대신, 3x3 filter를 여러 층 stacking해서 사용하면 파라미터 수가 감소하면서도 더 깊은 네트워크를 구성함으로써, 더 좋은 성능을 낼 수 있다는 점입니다.
ResNet (2015)
ImageNet Large-Scale Visual Recognition Challenge 2015에서는 ResNet이 우승을 차지했습니다. 무려 152 layer를 사용하여 사람의 Error rate인 약 5%보다 더 낮은 Error rate (3.57%)를 얻은 ResNet에 대해 정리해봅시다.
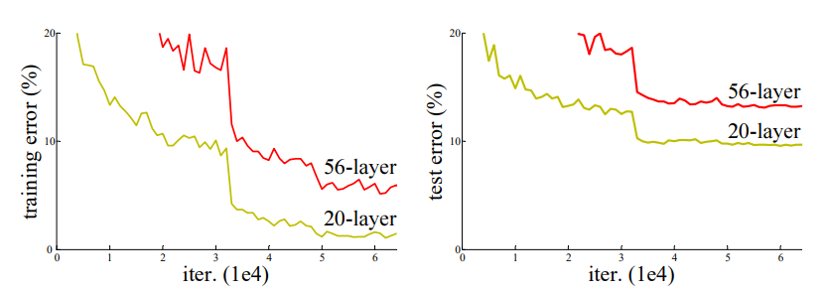
ResNet의 저자들은 네트워크가 깊어짐에 따라 성능이 어떻게 변화하는지를 테스트해보았습니다. 네트워크가 깊어지면 성능이 좋아져야 할 것 같은데, 오히려 Training과 Test 모두에서 Error rate가 더 높은 것을 발견했습니다. 이 문제를 해결하기 위해 고민을 시작했습니다.
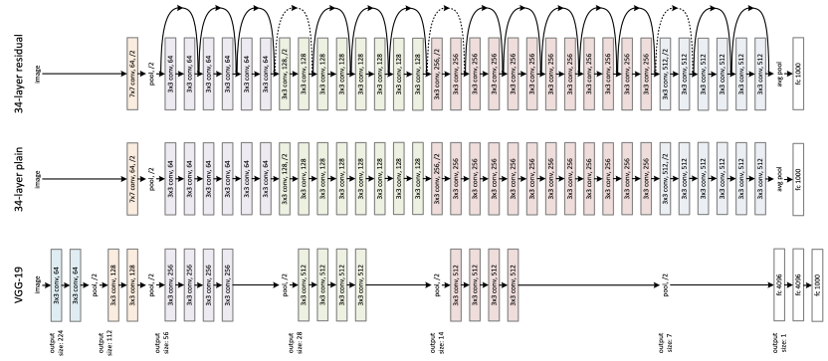
그 결과, Resnet의 저자들은 Skip connection이 사용된 Residual learning 이라는 개념을 새로 도입해서 네트워크를 더 깊게 만들 수 있었습니다.
그 외에도 dropout을 사용하지 않거나, 3x3 filter만 사용하고, 복잡도를 줄이기 위해 max-pooling을 최소화했다는 특징을 갖습니다.
Skip connection
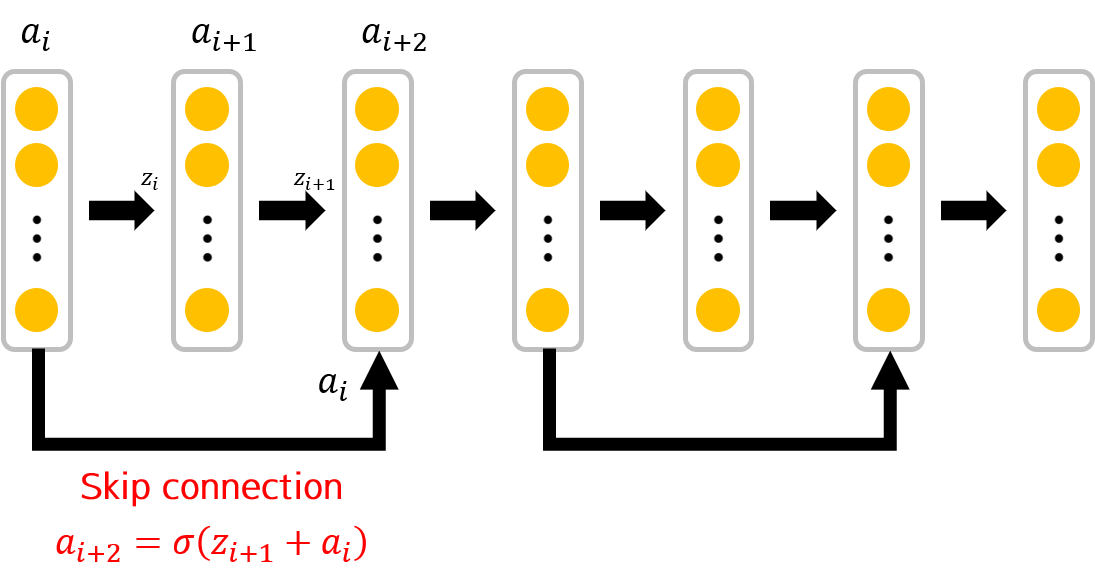
Skip connection이라는 것은 앞단의 입력값을 뒤의 레이어의 입력값으로 넣는 것인데, 그림으로 보면 더 이해가 잘 될겁니다.
단순히 입력과 출력이 연결되기 때문에, 파라미터 수가 증가하지 않고, 단순 덧셈 몇 번 외에는 연산량의 증가도 없습니다.
DenseNet (2017)
마지막으로 Dense Net에서는 앞서 ResNet에서 사용된 Skip connection을 더 Dense하게 사용했다는 특징을 갖습니다.
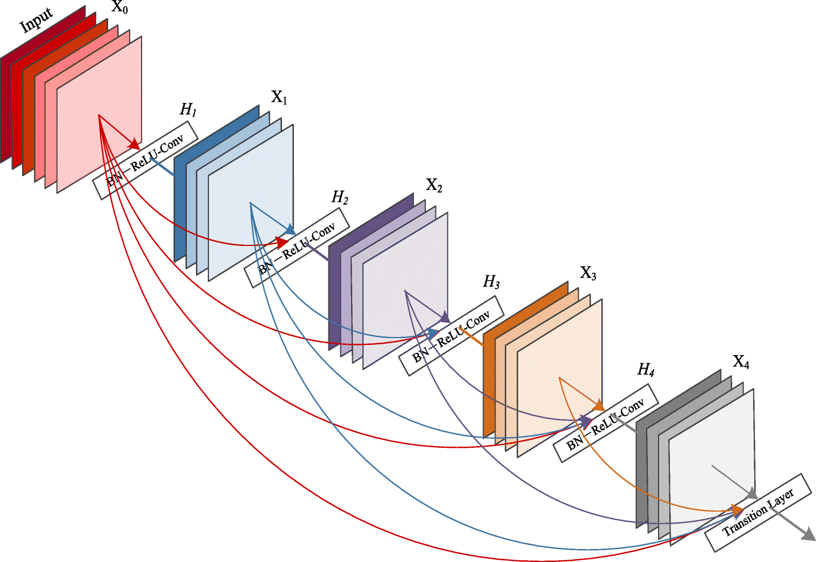
ResNet에서는 Skip connection이 띄엄띄엄 일어났지만, Dense Net에서는 그림에서 보다시피, 각 레이어들간의 Skip connection이 상당히 많이 일어납니다. 이를 통해 Gradient descent가 더 잘 일어나도록 네트워크를 구성했다고 합니다.
이번 포스팅에서는 LeNet-5, AlexNet, Inception (GoogLeNet), VGGNet, ResNet, DenseNet을 정리해보았습니다.
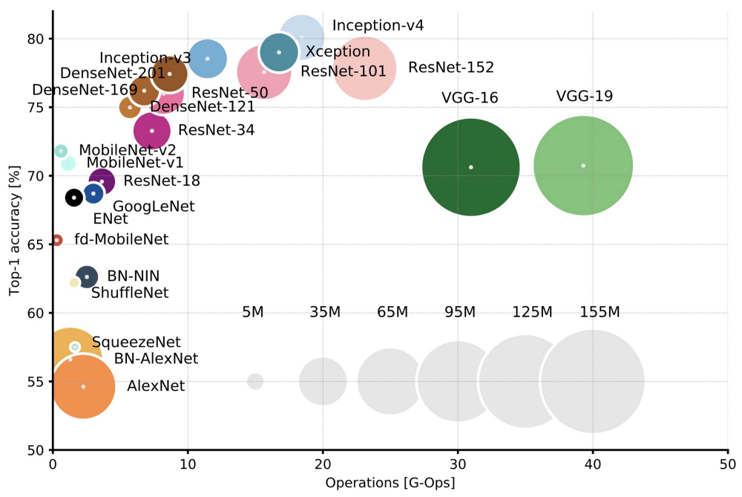
각 모델의 성능과파라미터 수를 정리한 표입니다. 파라미터 수가 증가함에 따라 성능이 증가하긴 하지만, 꼭 그런 것은 아닌 것을 보면, 네트워크를 최적화하는 방법에 대한 연구가 왜 많이 일어나는 지 알 수 있을 것 같습니다.
Leave a comment