
Classification for MEDIA (6) Evaluation metrics for classification (분류모델 평가 지표)
이전 포스팅: Classification for MEDIA (5) Overcome small dataset
이전 포스팅에서는 Medical image dataset의 특징인 적은 샘플 수를 극복하기 위한 여러 방법들을 정리했습니다
이번 포스팅에서는 분류 모델을 평가하는데 사용되는 여러가지 지표 (Sensitivity, Specificity, Precision, AUROC, F1 score, accuracy)를 정리해보고자 합니다.
Evaluation for classification model
모델 학습을 열심히 했다면, 이 모델이 얼마나 좋은 모델인지, 어떻게 평가할 수 있을까요?
가장 간단한 평가 지표는 정확도 (Accuracy)입니다. 전체 샘플 중 정답의 비율이라는, 누구나 알고 있는 간단한 식이죠. 하지만, 정확도만으로는 모델을 정확하게 평가할 수 없습니다. 예시로 살펴봅시다.
Idea classification model
가장 이상적인 형태의 분류모델은 위와 같은 결과를 보여야 합니다.
모든 Positive (양성; Cancer) 자극에 대해서는 Positive 라고 응답하며, 모든 Negative (음성; Normal) 자극에 대해서는 Negative라고 응답해야 합니다.
Real classification model
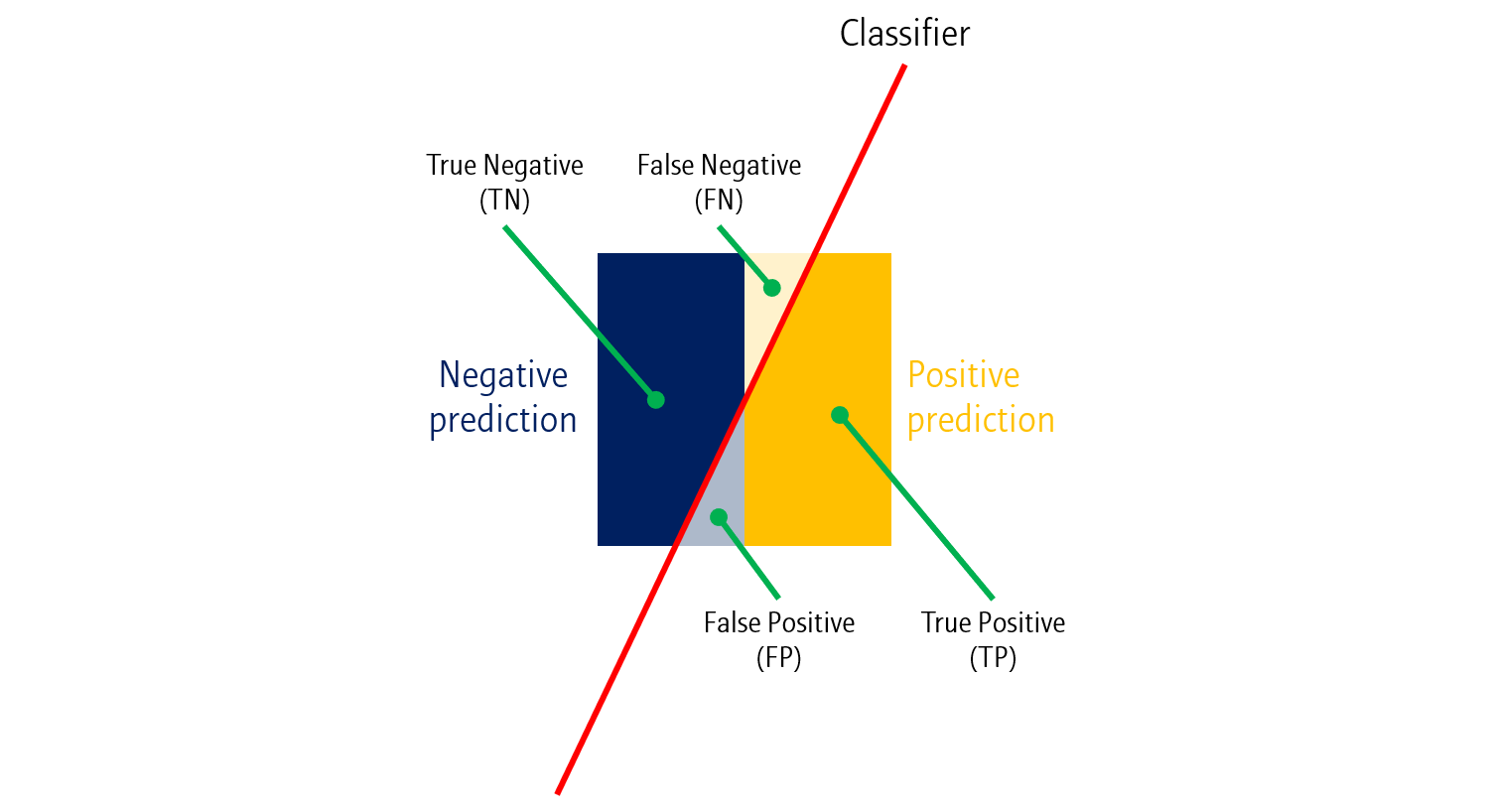
하지만 현실은 그리 녹록치 않습니다. 실제 분류모델들은 Test 시 빨간 선과 같이 살짝 빗겨나가게 분류를 합니다. 몇 가지 용어가 등장하는데 천천히 정리해봅시다.
- True Positive (TP): 실제로 Positive인데, 예측값도 Positive인 샘플 수
- False Positive (FP): 실제로 Negative인데, 예측값이 Positive인 한 샘플 수
- True Negative (TN): 실제로 Negative인데, 예측값도 Negative인 샘플 수
- False Negative (FN): 실제로 Positive인데, 예측값이 Negative인 샘플 수
즉, 뒤의 Positive/Negative는 예측값을 나타내며, 앞의 True/False는 정답 유무를 나타낸다고 보면 됩니다.
Accuracy
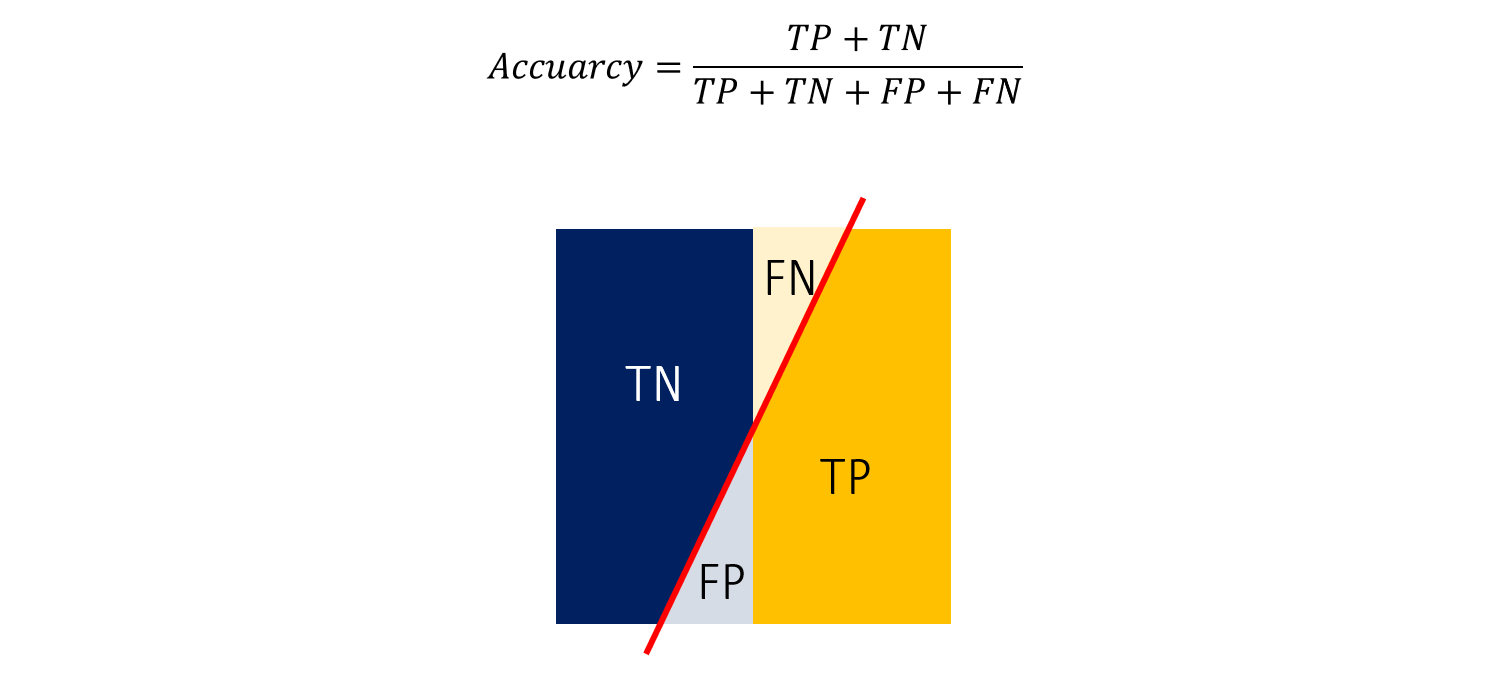
따라서 정확도 (Accuracy)는 위와 같이 모든 샘플 중 \(TP+TN\)의 비율로 나타낼 수 있습니다.
Problem of accuracy
앞서 말했듯, 정확도는 완벽한 평가지표가 아닙니다.
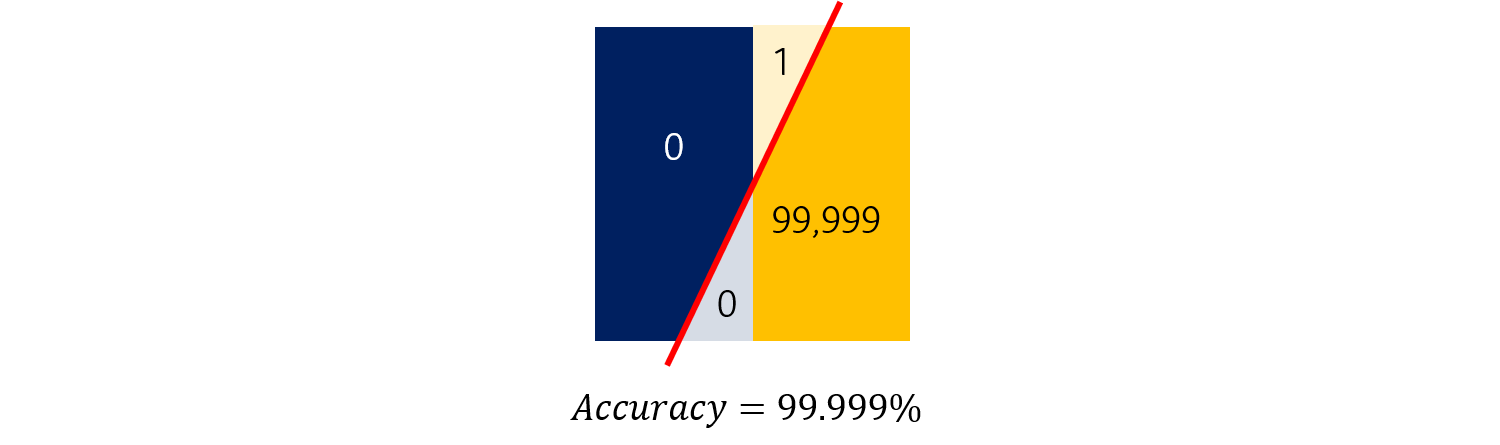
일반적으로 10,000명 중 1명이 암에 양성 (Positive)이라고 할 때, 만약 모델이 모든 사람들을 음성 (Negative)라고 판정해버리면 어떻게 될까요?
정확도로 이 모델을 평가하면, 이 모델은 무려 99.999%의 정확도를 지닌 파워풀한 모델입니다. 하지만, 1명뿐인 암환자를 예측하지 못했다는 점에서 이 모델은 좋은 모델이라고 말할 수 없습니다.
Sensitivity, Specificity, and Precision
다음 세 가지 평가지표는 각각 다른 종류의 정답율을 나타냅니다.
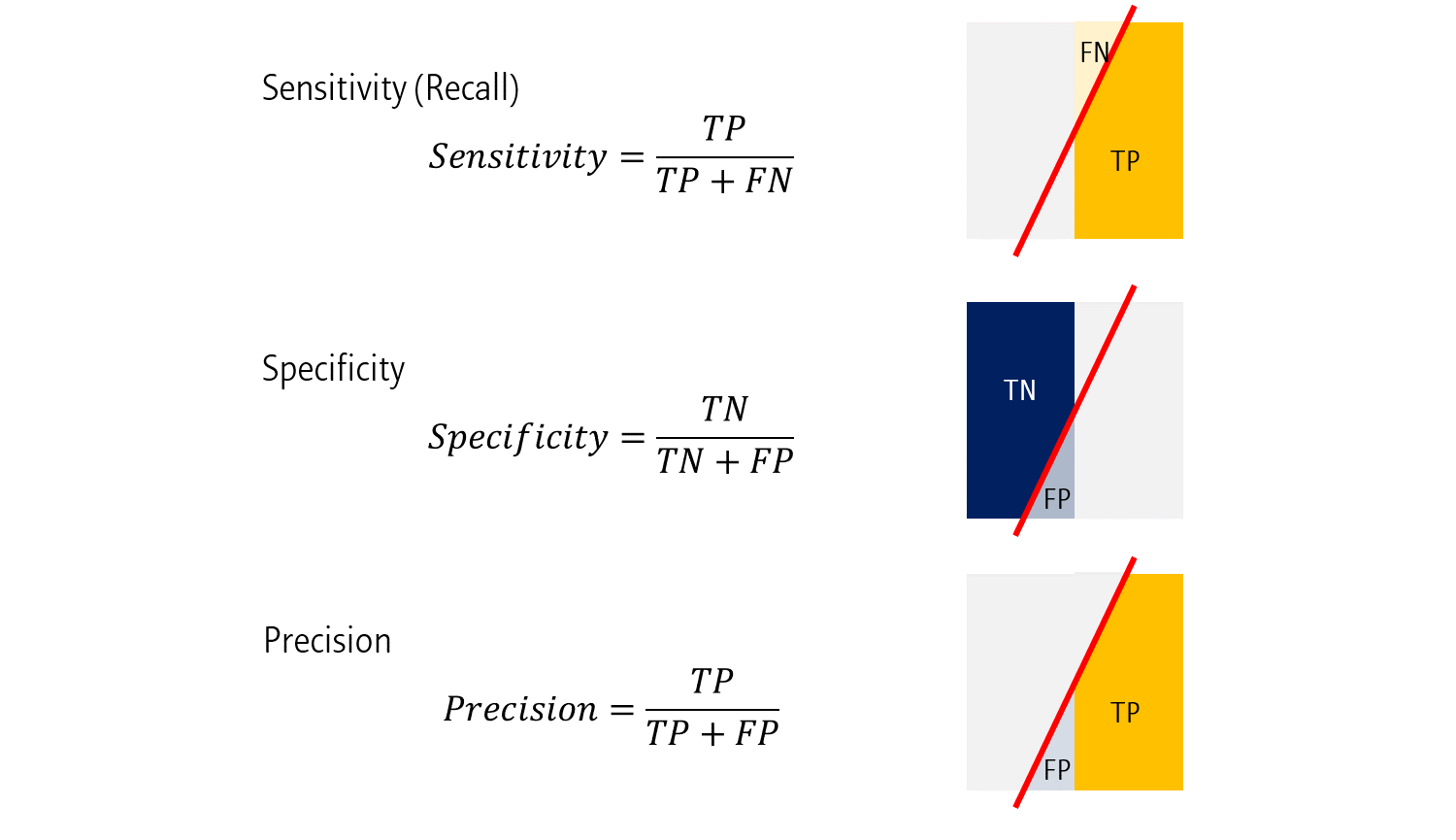
- Sensitivity는 \(\frac{TP}{TP+FN}\)로 나타내집니다. 즉, 모든 Positive 샘플 중, 정답의 비율을 나타냅니다.
- Sensitivity는 \(\frac{TN}{TN+FP}\)로 나타내집니다. 즉, 모든 Negative 샘플 중, 정답의 비율을 나타냅니다.
- Precision은 조금 다릅니다. \(\frac{TP}{TP+FP}\)로 나타내집니다. 즉, 모델이 예측값을 Positive라고 한 것 중, 진짜 Positive의 비율입니다.
Sensitivty와 Precision으로 앞의 모델을 다시 평가해보면, 각각 \(\frac{1}{99999}\), \(\frac{0}{99999}\)으로, Sensitivity와 Precision의 관점에서는 이 모델은 굉장히 안 좋은 모델이라고 말할 수 있습니다.
ROC (Receiver Operator Characteristics) curve
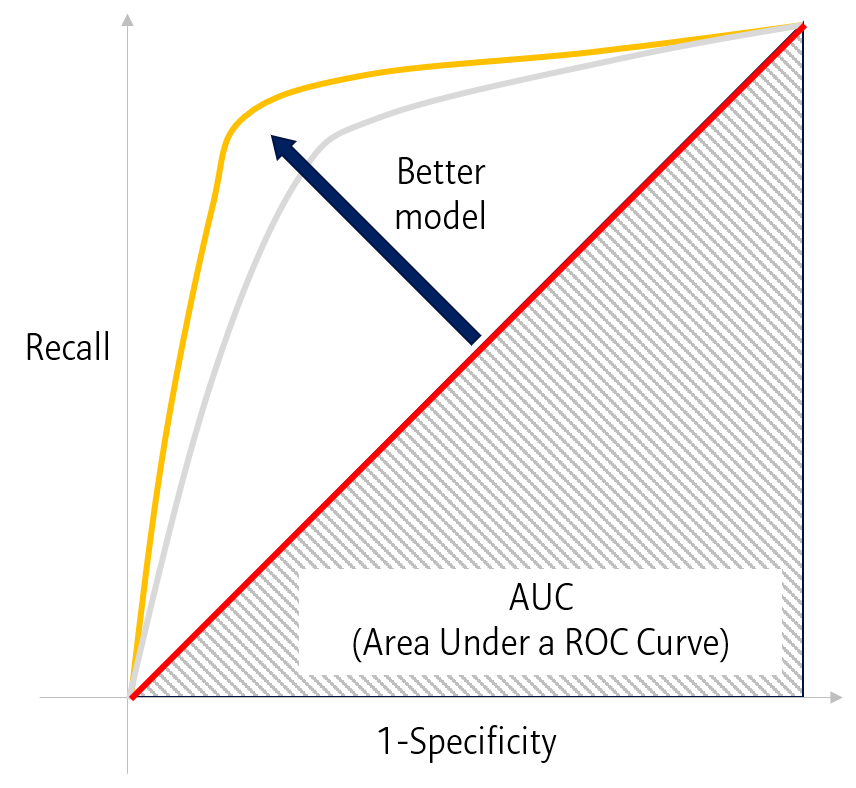
또 다른 지표로 ROC curve를 사용할 수 있습니다. ROC curve는 1-Specificity와 Recall의 비율로 나타내지는 그림으로, 좌상단으로 커브가 휠 수록, 더 좋은 모델이라고 평가할 수 있습니다.
ROC curve의 우하단 면적을 계산한 것을 AUC 또는 AUROC (Area Under ROC curve)라고 하는데, 이 값 또한 모델을 평가하는 정량적인 지표로 사용될 수 있습니다.
F1 score
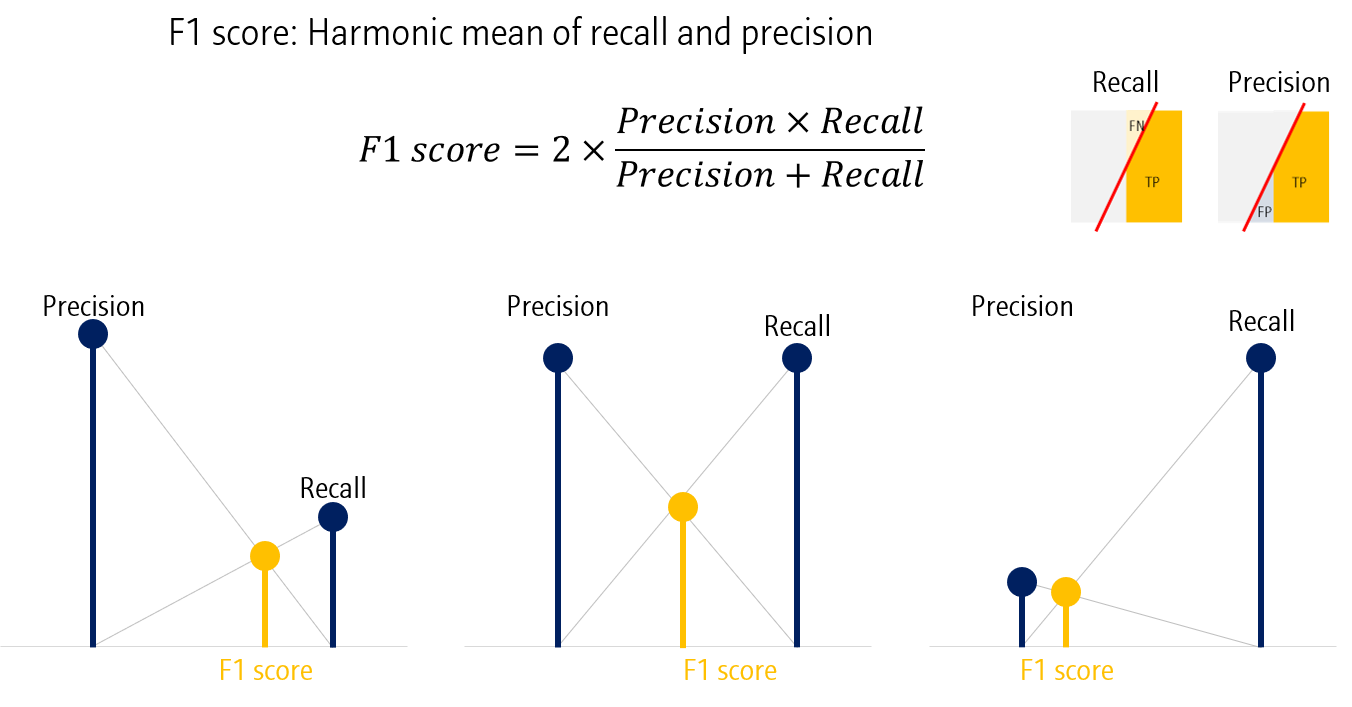
마지막 지표는 F1 score입니다. F1 score는 Precision과 Recall의 조화평균입니다. 따라서, Precision과 Recall이 모두 높아야만 높은 F1 score를 얻을 수 있습니다.
F1 score는 주로 Imbalanced dataset을 평가하는데 사용되는 지표입니다.
Evaluation metric for multi-class classification model
위 예시에서는 Positive/Negative의 binary classification model을 평가하는 지표를 정리했습니다.
만약 class의 종류가 여러 개라면 어떨까요? Binary classification model 평가지표와 동일한 지표를 사용합니다. 다만, 계산이 조금 복잡해집니다.
예를 들어, A,B,C,D로 이미지를 분류하는 4-class classification model을 생각해봅시다.
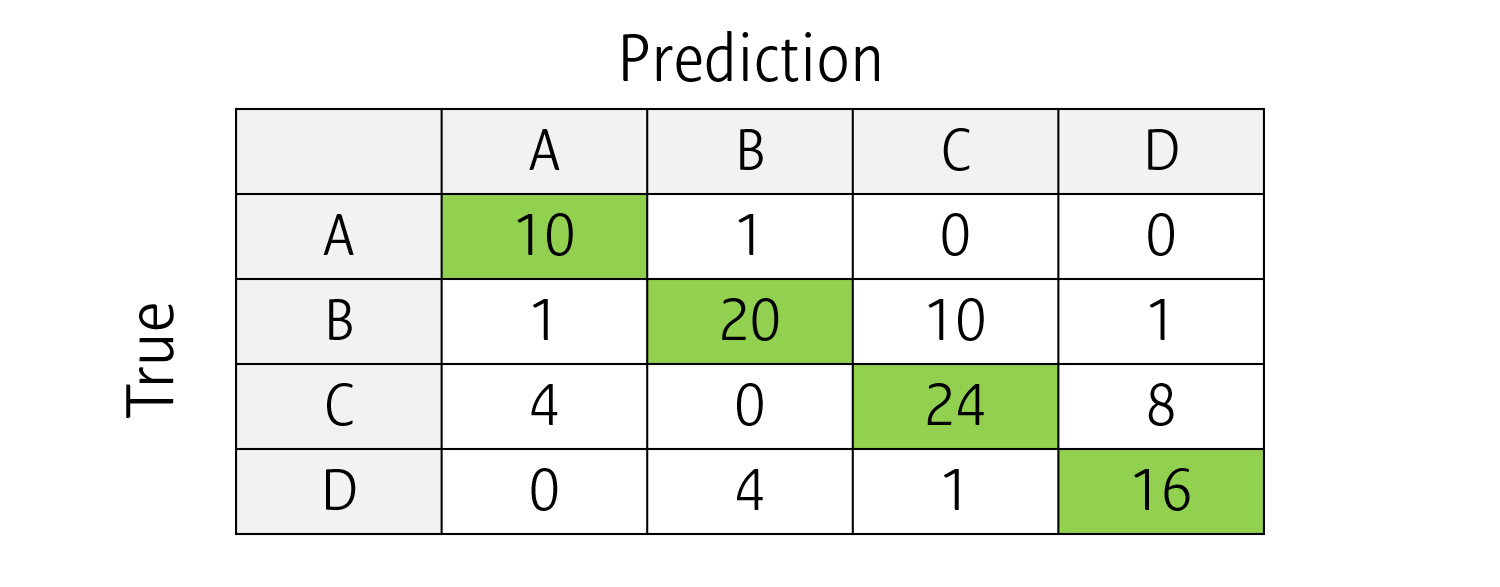
실제 정답과 예측값에 따라 위와 같은 Confusion matrix를 만들 수 있습니다. Confusion matrix의 diagonal element 합의 비율로 Accuracy를 간단히 계산할 수 있습니다.
나머지 (Sensitivity, Specificity, Precision 및 이를 이용하는 AUC, F1 score 등) 지표들은 각 클래스를 기준으로 Binary classification을 한 것처럼 생각해서 계산할 수 있습니다.
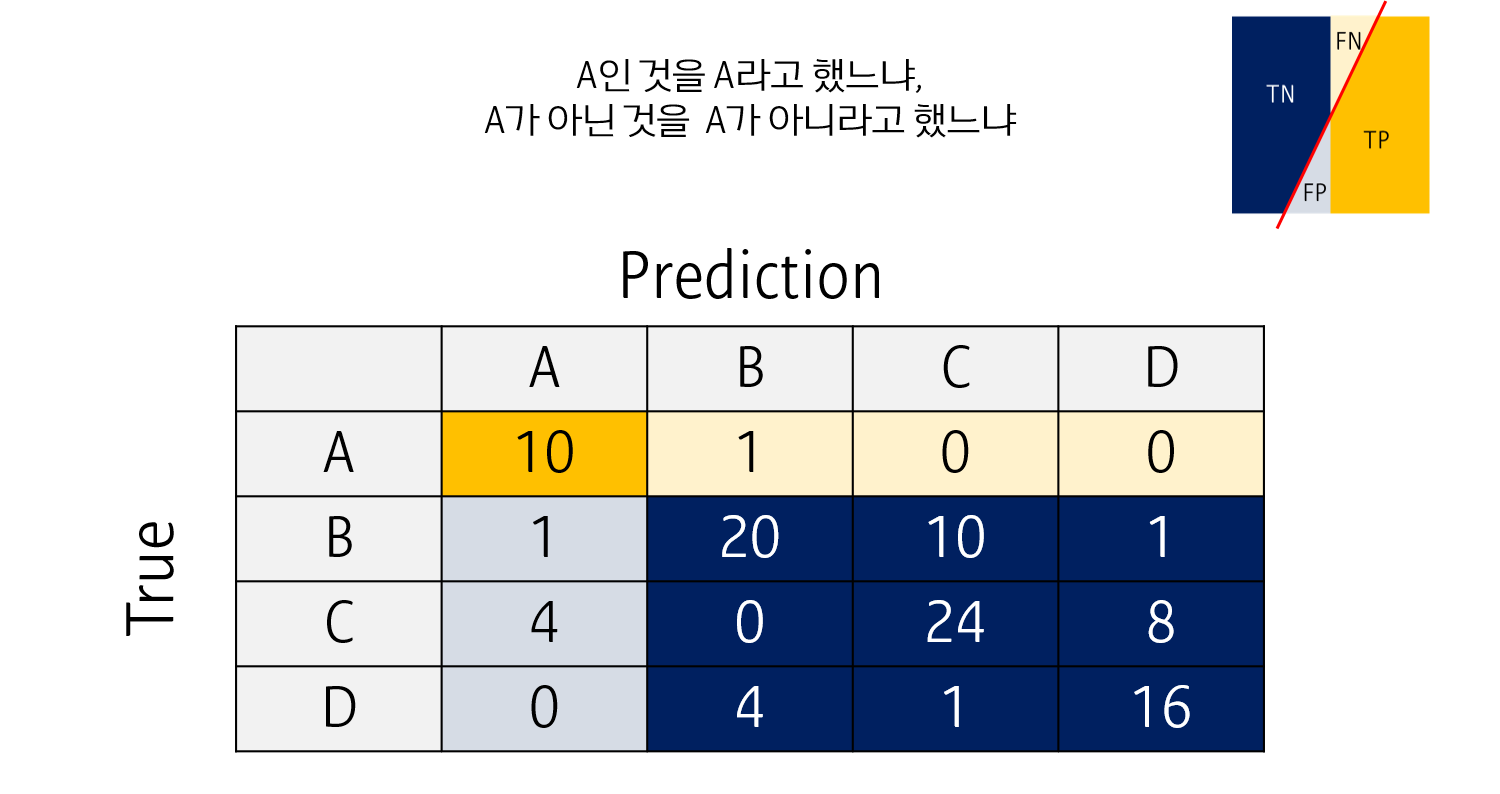
예를 들어 A class에 대해서는, confuision matrix를 위와 같이 다시 변환할 수 있습니다. A만이 정답 (Positive)이고, B, C, D 중 무엇이라고 하든 이를 Negative라고 응답했다고 생각합니다. 이렇게 되면 Sensitivity, Specificity, Precision를 계산할 수 있습니다.
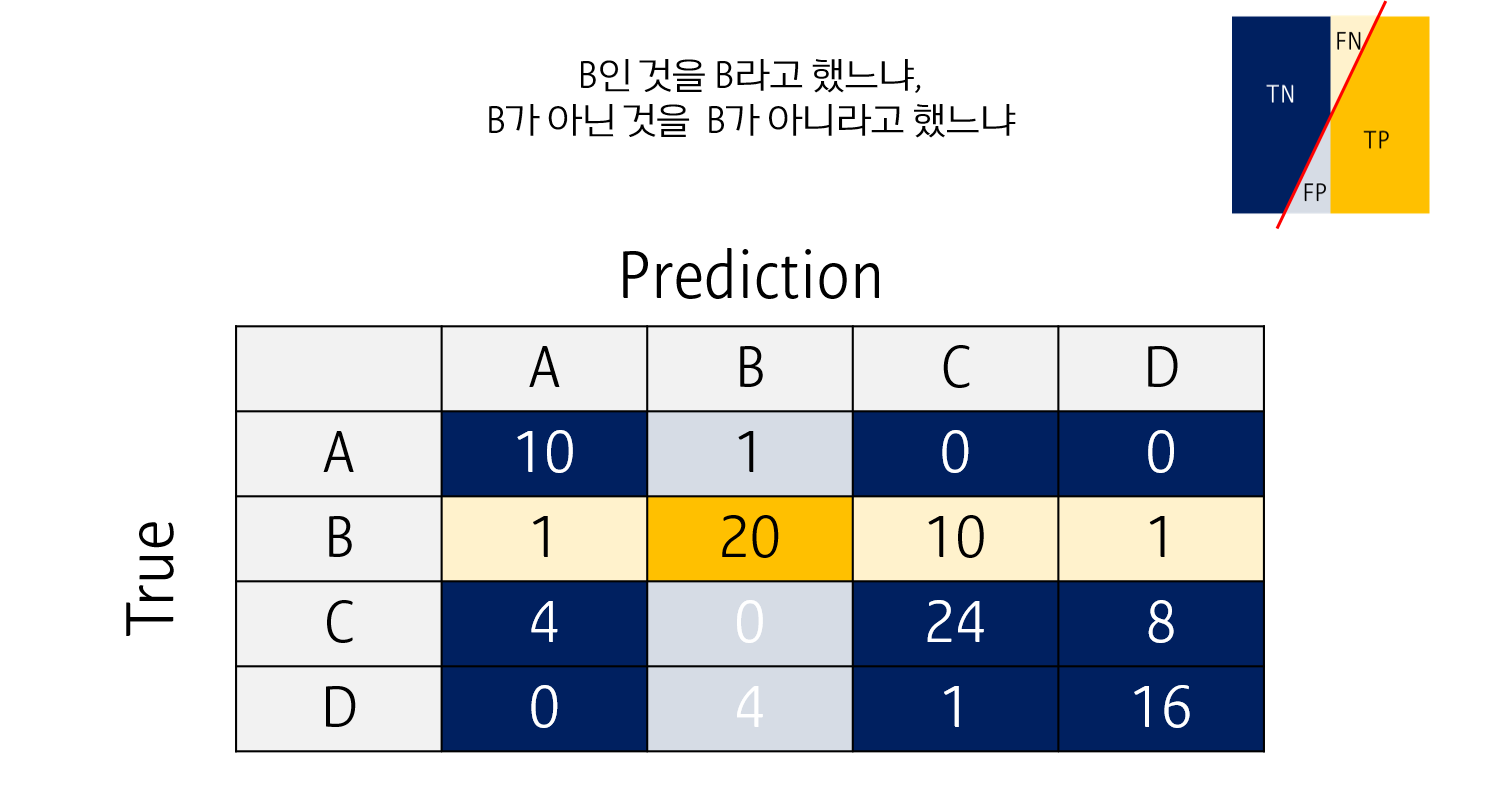
모든 클래스에 대해 지표를 계산한 뒤, 이를 평균내어 사용합니다.
다음 포스팅에서는 Feature selection 방법들을 정리해보고자 합니다
다음 포스팅: Classification for MEDIA (7) Feature selection and extraction
Leave a comment